Руководство пользователя
Tarantool Column Store – колоночная транзакционно-аналитическая СУБД, построенная на платформе Tarantool Enterprise Edition. TCS наследует от Tarantool базовые возможности хранения и масштабирования:
- данные хранятся в оперативной памяти;
- хранение персистентно;
- доступны механизмы репликации и шардирования.
TCS относится к гибридному классу систем хранения HTAP (Hybrid transactional/analytical processing). Хранилище данных реализовано средствами in-memory СУБД Tarantool. Для работы с данными в колоночном формате используется движок обработки данных MemCS. Такая архитектура позволяет добиться оптимальной производительности аналитических запросов (OLAP) наряду с характерной для Tarantool высокой производительностью при транзакционной нагрузке (OLTP).
Ниже объясняются детали реализации основных механизмов TCS:
Основное хранилище данных TCS работает с данными в колоночном формате.
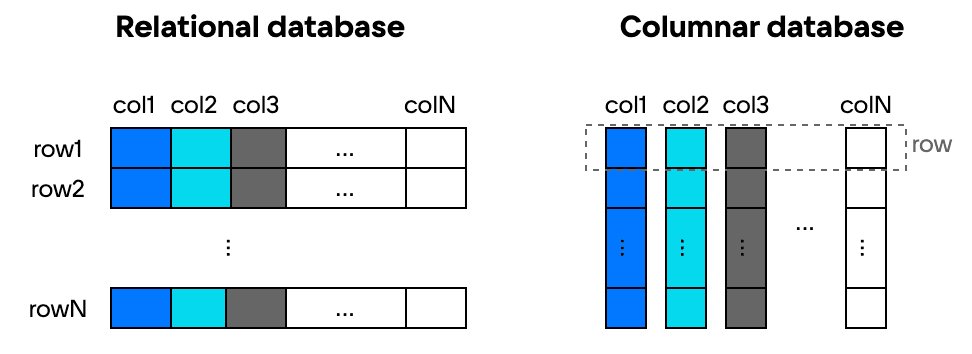
Ключевое отличие колоночных СУБД от реляционных СУБД с табличным хранением -- использование колонки в качестве единицы хранения вместо таблицы. В реляционной СУБД все поля одного объекта хранятся рядом в виде одной строки таблицы. В свою очередь, в колоночной рядом располагаются все значения одного поля таблицы, а поля одного объекта разнесены по соответствующим колонкам и не хранятся вместе.
Использование колоночного формата позволяет оптимизировать работу TCS под нагрузкой, характерной для аналитических задач (OLAP), то есть при большом количестве запросов на чтение и вычисление агрегатов.
Как гибридное решение, TCS предполагает работу под транзакционной нагрузкой на запись. Для консистентности чтения данных в таких условиях TCS использует представления для чтения (read view) – снимки хранилища данных в конкретный момент времени.
В каждый момент времени в TCS существует одно актуальное представление на чтение.
Оно обновляется раз в rv_update_ms миллисекунд. Когда приходит запрос
на чтение данных, для него используется актуальное представление.
Чтение выполняется в многопоточном режиме. Каждый поток, выполняющий запрос на чтение,
использует свое представление. В системе хранится набор всех используемых в данный момент
представлений, то есть тех, из которых еще выполняется чтение в рамках выполнения запросов.
Когда обработка запроса завершена, и при этом уже создано более актуальное представление,
то представление, которые использовалось для этого запроса, помещается в очередь
на удаление. Представления из этой очереди удаляются при следующей итерации цикла
сборщика мусора (раз в rv_update_ms миллисекунд).
Подробнее о представлениях на чтение см. документацию Tarantool EE.
Доступ к данным осуществляется по протоколам SQL Arrow Flight и HTTP. Запросы по всем протоколам принимаются в формате SQL.
В зависимости от режима работы кластера, запросы можно отсылать:
- напрямую на узлы-хранилища (Storage) – они обрабатывают все виды запросов к данным;
- через узлы-маршрутизаторы (Scheduler) – они автоматически перенаправляют запросы на узлы Storage.
Кластер TCS может работать в одном из двух режимов: проксирования или шардирования.
В режиме проксирования:
- В каждом экземпляре БД в кластере хранятся одинаковые данные.
- Запросы от клиентов могут автоматически перенаправляться на узлы Storage с помощью узлов Scheduler.
- При необходимости возможно отсылать запросы напрямую на конкретный узел Storage.
В режиме шардирования:
- В разных экземплярах БД хранятся разные части общего массива данных.
- С помощью узлов Scheduler, запросы от клиентов автоматически перенаправляются на узлы Storage с учетом разбиения данных на шарды.
- Отсылать запросы напрямую на конкретный узел Storage запрещено.
Модель данных в TCS создается и изменяется с помощью инструкций SQL DDL.
TCS использует табличную модель данных, характерную для большинства СУБД, использующих SQL:
- Данные хранятся в таблицах;
- Один хранимый объект формирует одну строку таблицы;
- Структура таблицы определяется набором ее столбцов – колонок;
- Каждая колонка содержит данные одного типа.
Список поддерживаемых типов данных приведен в разделе Типы данных.
Для логической организации таблиц в TCS используется понятие схемы (schema) -- именованного пространства хранения таблиц. Каждая таблица может содержаться только в одной схеме. Имена таблиц в разных схемах могут повторяться. Схемы агрегируются в каталоги – аналоги баз данных.
Таким образом, полная иерархия хранения данных в TCS выглядит так:
каталог.схема.таблица
По умолчанию используется каталог tcs и схема public.
В TCS используются примитивные типы данных Apache Arrow. Поддерживаются следующие типы:
Тип | Описание |
|---|---|
i8 | 8-битное знаковое целое |
i16 | 16-битное знаковое целое |
i32 | 32-битное знаковое целое |
i64 | 64-битное знаковое целое |
u8 | 8-битное беззнаковое целое |
u16 | 16-битное беззнаковое целое |
u32 | 32-битное беззнаковое целое |
u64 | 64-битное беззнаковое целое |
f32 | 32-битное с плавающей точкой |
f64 | 64-битное с плавающей точкой |
decimal | десятичное число с шириной 128 или 256 бит |
decimal128 | десятичное число с шириной 128 бит |
decimal256 | десятичное число с шириной 256 бит |
utf8 | строка UTF-8 |
bool | логический: true или false |
ts | UNIX timestamp в наносекундах |
Десятичные числа в TCS задаются в формате Apache Arrow и имеют следующие характеристики:
- ширина в битах (bit width): 128 или 256 бит
- масштаб (scale)
- точность (precision)
Ширина (bit width) может быть задана явно (decimal128 или decimal256), либо
вычисляться автоматически на основании точности (precision).
Для чисел с явно заданной шириной (bit width) используются соответствующие значения точности (precision):
- для
decimal128точность = 38 - для
decimal256точность = 76
Точность (precision) также может быть задана явно или неявно:
-
Если она задана явно (например,
decimal(3, 2), здесь точность = 3), то:-
Выполняется следующая проверка для точности:
1 <= precision <= 76
-
Точность сводится к:
- 38 (если указанное значение точности <= 38)
- 76 (если указанное значение точности > 38)
-
-
Если она задана неявно (например,
decimal128(2)), то точность уже известна, исходя из ширины (например, дляdecimal128используется точность = 38).
Масштаб (scale) может быть задан только явно. Например, decimal(3, 2) (здесь масштаб = 2).
Для масштаба всегда выполняется следующая проверка:
0 <= scale <= precision
Пример SQL-инструкции с десятичными числами:
CREATE TABLE t (d1 decimal128 (9),d2 decimal256 (1),d3 decimal (4, 3),d4 decimal (39, 2),)
где:
-
decimal128(9)- bit width = 128
- scale = 9
- precision = 38
-
decimal256(1)- bit width = 256
- scale = 1
- precision = 76
-
decimal(4, 3)- bit width = 128
- scale = 3
- precision = 38 (поскольку 4 <= 38)
-
decimal(39, 2)- bit width = 256
- scale = 2
- precision = 76 (поскольку 39 > 38)
TCS не поддерживает хранение массивов (данных типа array), но разрешает передачу массива в запросе.
См. например функцию array_concat.
Для обращения к данным в хранилище Tarantool Column Store используются SQL-запросы.
TCS поддерживает следующие способы обращения к данным:
- SQL-запросы
SELECTчерез SQL и HTTP API – наиболее простой способ, подходящий для работы без нагрузки, например, для тестирования и отладки или единичного выполнения. - Аналитические расчеты – хранимые в TCS именованные процедуры, в которых доступен широкий спектр операций над данными с использованием всех поддерживаемых функций и операторов SQL.
- Представления для чтения (read views) – снимки хранилища данных в конкретный момент времени.
- Нематериализованные SQL-представления (non-materialized views in SQL) -- удобный способ обращаться к большим запросам, как к таблице.
Поддерживаемые операторы и функции SQL описаны в [ссылка](../reference#sql-reference[text=Справочнике по SQL]}.
).
Пример запроса на чтение всех объектов таблицы:
SELECT * FROM users
-
HTTP:
Отправьте POST-запрос на HTTP-адрес
/sql.Пример запроса на чтение всех объектов таблицы:
curl -u tcs:tcs -d 'SELECT * FROM users' http://localhost:7777/sqlПример запроса на чтение с фильтром:
curl -u tcs:tcs -d 'SELECT * FROM users WHERE id=1' http://localhost:7777/sqlПример чтения из схемы по умолчанию
tcs.schema:curl -u tcs:tcs -d 'SELECT * FROM users WHERE id=1' http://localhost:7777/sql
TCS позволяет выполнять аналитические расчеты над хранимыми данными.
Аналитический расчет – это процедура, которая содержит агрегирующие запросы к таблицам и колонкам и возвращает результат выполнения запросов. В аналитических расчетах можно использовать поддерживаемые операторы и функции SQL, описанные в [ссылка](../reference#sql-reference[text=Справочнике по SQL]}.
TCS поддерживает два вида аналитических расчетов:
- перманентные (хранятся в базе данных)
- временные (работают только в пределах сессии)
).
Запрос должен содержать SQL-оператор PREPARE, создающий подготовленное SQL-выражение (prepared statement)
Пример: расчет количества записей в таблице.
PREPARE plan(INT) AS SELECT count(*) FROM users WHERE age > $1
-
HTTP:
Отправьте POST-запрос на HTTP-адрес
/sql. В качестве значения используйте SQL-операторPREPARE, создающий подготовленное SQL-выражение (prepared statement).Пример: расчет количества записей в таблице.
curl -u tcs:tcs -d 'PREPARE plan(INT) AS SELECT count(*) FROM users WHERE age > $1' http://localhost:7777/sql
В качестве параметров для подготовленных SQL-выражений используйте типы данных PostgreSQL.
Чтобы выполнить существующий в TCS расчет, воспользуйтесь одним из двух интерфейсов: SQL или HTTP.
-
SQL:
Отправьте SQL-запрос с
EXECUTEчерез SQL-драйвер.Пример:
EXECUTE plan(0) -
HTTP:
Отправьте POST-запрос на HTTP-адрес
/sql. JSON-тело запроса должно содержать инструкцию EXECUTE, имя и входные параметры расчета.Пример:
curl -u tcs:tcs -d 'EXECUTE plan(0)' http://localhost:7777/sqlВ ответе TCS отправляет результаты выполнения в следующих секциях:
success– результаты успешно выполненных запросов;fail– информация о запросах, которые не удалось выполнить;timings– время, потраченное на разные этапы обработки запроса;plans– вывод EXPLAIN ANALYZE для планов, указанных в запросе.
(queries-computation-manage)
Чтобы получить список аналитических расчетов и их статусов,
отправьте запрос SELECT, содержащий функцию tcs_prepareds.
Пример запроса:
SELECT * FROM tcs_prepareds()
В ответе придёт список, содержащий имена и тела запросов, их зависимости и статусы.
Пример ответа:
name query depends_on status0 my_prepared PREPARE my_prepared A S SELECT 1 None Ready
Статус Ready указывает на то, что аналитический расчет готов. Если аналитический расчет
не готов (планируется к выполнению), его статус будет Planning.
Чтобы просмотреть текст конкретного аналитического расчета, отправьте запрос SELECT,
содержащий функцию tcs_prepareds и имя расчета.
Пример: просмотр текста существующего аналитического расчета my_prepared.
SELECT * FROM tcs_prepareds() WHERE name = my_prepared
TCS предполагает работу под постоянной транзакционной нагрузкой на запись. Для консистентности чтения данных в таких условиях TCS использует представления для чтения (read view) – снимки хранилища данных в конкретный момент времени.
В каждый момент времени в системе существует одно актуальное представление на чтение.
Оно обновляется раз в rv_update_ms миллисекунд.
Также есть очередь из используемых в данный момент представлений, из которых еще выполняется чтение в проходящих обработку запросах SQL и прочих.
Когда запрос на чтение обработан, и при этом уже есть более актуальное представление,
то представление, которые использовалось для этого запроса, помещается в очередь.
При следующей итерации цикла сборщика мусора (раз в rv_update_ms миллисекунд)
все представления из очереди удаляются.
Подробнее о представлениях на чтение читайте в документации Tarantool EE.
Нематериализованные SQL-представления удобны тем, что позволяют обращаться к большим запросам, как к таблице. Поскольку создаваемое представление не имеет физической формы, указанный запрос будет выполняться каждый раз при обращении к этому представлению.
Чтобы создать нематериализованное SQL-представление, отправьте SQL-запрос, содержащий SQL-оператор CREATE VIEW.
Пример: SQL-представление, содержащее список имен всех совершеннолетних лиц в таблице.
CREATE VIEW adults AS SELECT name FROM users WHERE age >= 18;
После создания нематериализованное SQL-представление становится доступно:
- для запросов на чтение,
- для аналитических расчетов,
- для использования в других нематериализованных SQL-представлениях; это означает, что в TCS можно создавать вложенные (иерархические) нематериализованные SQL-представления.
Пример: обращение к SQL-представлению adults из SELECT-запроса.
SELECT salary FROM users WHERE name IS IN (SELECT name FROM adults)
Чтобы просмотреть все доступные нематериализованные SQL-представления, отправьте запрос SELECT,
содержащий функцию tcs_views:
SELECT * FROM tcs_views()
Чтобы просмотреть текст конкретного SQL-представления, отправьте запрос SELECT,
содержащий функцию tcs_views и имя представления.
Пример: просмотр текста существующего SQL-представления adults.
SELECT * FROM tcs_views() WHERE name = adults
Чтобы заместить существующее SQL-представление, отправьте SQL-запрос, содержащий SQL-оператор CREATE OR REPLACE VIEW.
Пример: замещение существующего SQL-представления adults.
CREATE OR REPLACE VIEW adults AS SELECT name FROM users WHERE age >= 16
Чтобы удалить SQL-представление, отправьте SQL-запрос, содержащий SQL-оператор DROP VIEW и имя представления.
Пример: удаление существующего SQL-представления adults.
DROP VIEW adults
В TCS предусмотрены правила оптимизации для запросов на чтение шардированных данных:
RemotePushDownLocalizedPrepared
Правило оптимизации RemotePushDown позволяет исполнить всю возможную часть запроса
на одном шарде, для того чтобы по сети пересылался минимум данных. Без этой оптимизации
все данные из таблицы, необходимые для выполнения запроса, пересылались бы по сети
на экземпляр Scheduler, где дальше исполнялся бы сам запрос.
Далее рассмотрим на примерах, как это правило оптимизации влияет на обработку шардированных
запросов на чтение. Предположим, что у нас есть шардированная таблица t(a, b) и 3 шарда.
Рассмотрим простой запрос:
SELECT * FROM t
Запросив EXPLAIN на экземпляре Scheduler, можно увидеть физический план следующего вида:
RemoteExec: table=datafusion.public.t, partitioning=Hash([a@0], 3), filter=NoneUnionExecTarantoolExec: table=datafusion.public.t fields=[a, b], ...BufExec: table=datafusion.public.t fields=[a, b], ...
В этом плане есть узел RemoteExec, который отправляет нижележащий план на шарды
для последующего исполнения. Тот план, который он отправляет, назовем удаленным планом.
В нашем примере удаленный план – это план с корневым узлом UnionExec.
В описании RemoteExec мы видим следующее:
- есть соответствие между этим узлом и таблицей
t(table=); - партицирование данных производится по хэшу колонки
a(согласно схеме шардирования); - используется пустой фильтр.
В нашем примере таблица будет просканирована на 3 шардах, а все записи отправлены на экземпляр Scheduler и там объединены.
Рассмотрим более сложный запрос, где для выполнения не обязательно читать данные со всех шардов:
SELECT * FROM t WHERE a = 1
Здесь мы получаем физический план следующего вида:
RemoteExec: table=datafusion.public.t, partitioning=Hash([a@0], 1), filter=datafusion.public.t.a=1CoalesceBatchesExec: target_batch_size=8192FilterExec: a@0 = 1UnionExecTarantoolExec: table=datafusion.public.t fields=[a, b], ...BufExec: table=datafusion.public.t fields=[a, b], ...
В описании RemoteExec мы видим следующее:
- весь план проталкивается внутрь (push down) через
RemoteExec; - фильтрация выполняется полностью в рамках одного шарда, а по сети пересылаются уже отфильтрованные данные.
Здесь правило RemotePushDown пытается поднять RemoteExec как можно выше.
Для того чтобы посмотреть, как отработало то или иное правило оптимизации, можно
использовать запрос EXPLAIN VERBOSE. Он возвращает состояния плана после каждой
изменившей его оптимизации. Например, в нашем случае можно видеть, что первоначальный
физический план имеет такой вид:
FilterExec: a@0 = 1RemoteExec: table=datafusion.public.t, partitioning=Hash([a@0], 1), filter=datafusion.public.t.a=1UnionExecTarantoolExec: table=datafusion.public.t fields=[a, b], ...BufExec: table=datafusion.public.t fields=[a, b], ...
Здесь фильтрация осуществляется после сбора данных с шардов, а после прохода
правила оптимизации RemotePushDown фильтр проталкивается вниз через RemoteExec,
вследствие чего запрос становится лучше локализован в рамках шарда.
Правило RemotePushDown также может обеспечить выполнение частичной агрегации на шардах.
Рассмотрим запрос:
SELECT count(*) FROM t
Он имеет следующий физический план:
AggregateExec: mode=Final, gby=[], aggr=[count(*)]CoalescePartitionsExecRemoteExec: partitioning=UnknownPartitioning(3), filter=NoneAggregateExec: mode=Partial, gby=[], aggr=[count(*)]UnionExecTarantoolExec: table=datafusion.public.t fields=[], ...BufExec: table=datafusion.public.t fields=[], ...
Как мы видим, частичная агрегация была перенесена на шард. Заметим, что в этом примере
для RemoteExec уже не выводится table, а также используется UnknownPartitioning
вместо Hash. Это происходит из-за того, что после исполнения агрегации изменяется
выходная схема: поле a в ней больше не присутствует, но появляется поле count(*).
То, какие узлы можно проталкивать внутрь для исполнения на одном шарде, определяется следующими факторами:
-
Если в запросе указан фильтр, который читает лишь одно значение ключа шардирования (например,
a = $1), то запрос может быть полностью локализован и план будет полностью протолкнут подRemoteExec. -
В ином случае проталкивание производится до тех пор, пока шард может исполнить соответствующий узел самостоятельно (то есть пока для сбора данных шарду не нужны данные с других шардов). Например,
CoalescePartitionsExecне может быть исполнен локально, поскольку для него необходимо собрать данные со всех шардов, тогда какFilterExecможет быть исполнен локально.
Правило оптимизации LocalizedPrepared позволяет полностью предотвратить передачу
физического плана с экземпляра Scheduler на экземпляр Storage при исполнении
обоих следующих условий:
- Исполняется аналитический запрос (prepared statement).
- План был полностью локализован.
В таком случае при исполнении аналитического запроса будет использоваться план следующего вида:
PreparedStatementExec: name=query, mode=local {from_cache: true}RemoteExec: table=datafusion.public.sharded_by_indexed_string, partitioning=Hash([a@0], 1), filter=NonePreparedStatementExec: name=query, mode=remote, metrics=[]\n
Данный план следует читать так:
"Исполняется аналитический запрос, локальный для экземпляра Scheduler.
Его план состоит из однопартицированного RemoteExec, который отправляет
удаленный план на экземпляр Storage для исполнения аналитического запроса."
В этом случае вместо тяжелого плана будет отослан всего один узел (PreparedStatementExec).
Далее экземпляр Storage сам запланирует аналитический запрос с этим названием
(либо возьмет план для исполнения из кэша) и исполнит его.
Для выполнения операций модификации данных в Tarantool Column Store используются
запросы SQL DML. Их можно отсылать как через SQL-драйвер, так и
в виде POST-запроса на HTTP-адрес /sql.
TCS поддерживает несколько вариантов вставки данных в таблицу:
- SQL-запрос с помощью SQL-драйверов;
- SQL-запрос на HTTP-адрес
/sql; - HTTP-запрос с данными в формате JSON на HTTP-адрес
/insert.
Для вставки данных в таблицу используются SQL-запросы с оператором INSERT
вида INSERT INTO table_name { VALUES ( expression [, ...] ) [, ...] | query }.
В одном запросе можно передавать как один, так и несколько объектов для вставки. TCS обрабатывает объекты в том порядке, в каком они указаны в запросе.
В значениях полей можно указывать как конкретные значения, так и null.
Пример:
INSERT INTO target_table VALUES (1, 'One'), (2, 'Two');
Также в запросах можно использовать аргументы-заполнители (placeholders).
Вставка данных чере HTTP-адрес /sql производится с помощью SQL-запросов, полностью аналогичных
тем, что используются при вставке данных через SQL-драйверы.
Алгоритм обработки запросов и их быстродействие здесь также аналогичны.
HTTP-адрес /insert используется для выполнения запросов на вставку как более быстрая
альтернатива SQL-драйверам и HTTP-адресу /sql.
Вставка через HTTP-адрес /insert работает быстрее, поскольку не требует
ресурсоемкого построения планов.
При этом способе вставки производятся лишь 2 дополнительных действия:
- проверка соответствия типов переданных значений и типов колонок;
- перевод данных в необходимый формат для вставки в Tarantool.
Через HTTP-адрес /insert данные передаются не с помощью SQL-запросов, а с помощью
HTTP-запросов в сериализованном виде в формате JSON.
Требования к HTTP-запросам:
- Запросы отсылаются на HTTP-адрес вида
/insert/$name, где/$name– это имя таблицы. - Тело запроса должно содержать массив описаний вставляемых объектов.
- Для каждой строки указываются значения вида
"имя_колонки": значение. Их требуется указывать для всех колонок, которые есть в таблице. - Порядок колонок в запросе может быть любым. Например,
[{ "a": 1, "b": 2 }]эквивалентно[{ "b": 2, "a": 1 }]. - Значения
nullможно опускать. Например,[{ "a": 1, "b": null }]эквивалентно[{ "a": 1 }]. - В заголовке запроса нужно обязательно указывать
content-type: application/json.
Пример: вставка данных в таблицу target_table с помощью утилиты curl.
curl -u 'tcs:tcs' -H 'Content-Type: application/json' -d '[{"a":1, "b":-1}, {"a":2, "b": -2}]' http://localhost:7777/insert/target_table
Для вставки в таблицу объектов из выборки используйте SQL-запрос вида
INSERT INTO table_1 SELECT attribute FROM table_2.
Пример:
INSERT INTO names SELECT name FROM users
В операциях вставки из выборки можно использовать все имеющиеся в TCS возможности SELECT-запросов, например осуществлять выборку из нескольких таблиц (оператор JOIN) и задавать условия с помощью оператора WHERE. Подробнее см. Справочник по SQL > Инструкция SELECT.
Порядок полей таблиц и типы должны совпадать. Например, возьмем две таблицы:
- таблицу
names, которая содержит 2 поля,nameиage(именно в таком порядке они объявлены в модели данных); - таблицу
users, которая содержит поляaddress,age,nameи прочие.
Следующий запрос составлен с учетом порядка полей в этих таблицах:
INSERT INTO names SELECT name, age FROM users
Для обновление данных в таблице используйте запрос с SQL-оператором UPDATE.
Поддерживается следующий синтаксис запросов:
UPDATE table_nameSET column1 = value1, column2 = value2, ...WHERE condition;
Пример:
UPDATE namesSET name = 'Anna Danilova', age = '32'WHERE id = 10
Для удаления объектов из таблиц используйте запрос с SQL-оператором DELETE.
Пример:
DELETE FROM a WHERE i > 1 LIMIT 100
Эта возможность не поддерживается в текущей версии TCS.
Эта возможность не поддерживается в текущей версии TCS.
На HTTP-адрес /sql можно отправлять сразу несколько SQL-инструкций, разделенных
точкой с запятой (;). Это могут быть любые SQL-инструкции, поддерживаемые TCS.
TCS обрабатывает инструкции в указанном порядке и возвращает список статусов.
Если обработка какой-либо инструкции заканчивается ошибкой, то TCS прекращает обработку инструкций и возвращает список статусов.
Пример запроса:
POST http://localhost:7777/sql HTTP/1.1Content-Type: application/jsonSELECT name FROM users; INSERT INTO names SELECT name FROM users; SELECT * FROM names ORDER BY name
Если, например, вторая инструкция (INSERT INTO names SELECT name FROM users) завершится ошибкой,
то третья инструкция тоже не выполнится.
В текущей версии TCS ни в одном из интерфейсов (HTTP, JDBC\ADBC) не поддерживается интерактивное управление транзакциями (COMMIT, ROLLBACK).
Однако, если SQL-операция по изменению данных (DELETE, INSERT, UPDATE) затрагивает большой массив данных (больше максимального размера пакета), то она разбивается на несколько под-операций, которые далее обрабатываются как единая транзакция. При этом если какая-либо из под-операций завершается некорректно, то оставшиеся под-операции не выполняются, но (в отличие от классических транзакций) результат предыдущих под-операций не откатывается.
Пример: При удалении 50 тысяч строк создается 7 под-операций удаления (50000 / 8192 примерно равно 6,1). Если пятая под-операция из этих 7 завершится некорректно, то эта и остальные две под-операции не применятся, но результат первых 4 операций останется в базе.
TCS поддерживает отправку параметризованных SQL-запросов по HTTP. Параметры запроса передаются списком в соответствующей переменной:
-
args– список параметров при однократном вызове запроса (поддерживается для всех видов запросов):curl -u tcs:tcs -X POST -H "Content-Type: application/json" -d '{ "query": "SELECT * FROM t WHERE a>$1", "args": [0] }' http://localhost:7777/sql -
bulk_args– список списков параметров для множественных вызовов (поддерживается для запросов INSERT, UPDATE, DELETE):curl -u tcs:tcs -X POST -H "Content-Type: application/json" -d '{ "query": "INSERT INTO t VALUES($1, $2)", "bulk_args": [[1,1], [2,2]] }' http://localhost:7777/sql
В режиме проксирования экземпляры Scheduler могут принудительно отправлять запросы лишь на те экземпляры Storage, которые настроены на работу только в режиме чтения (read-only) -- либо наборот, принудительно исключать такие экземпляры Storage из маршрутизации.
Для отправки запроса на определенный вид экземпляров Storage нужно в заголовке запроса указать
параметр x-tcs-route и тот тип экземпляров Storage, на которые нужно маршрутизировать запрос:
roдля отправки на экземпляры, настроенные только на чтение;rwдля исключения read-only экземпляров из маршрутизации (в этом случае запрос будет отправлен на экземпляр, настроенный на чтение-запись);anyдля отправки на все типы экземпляров (это аналогично тому, когда заголовокx-tcs-routeне указан).
Балансировка нагрузки для таких запросов осуществляется только среди указанного типа экземпляров Storage.
Далее приводятся примеры отправки запросов на RW-экземпляр Storage для разных интерфейсов.
-
Для ADBC/JDBC:
header_key = f"{DatabaseOptions.RPC_CALL_HEADER_PREFIX.value}x-tcs-route"db_kwargs[header_key] = rwself.conn = adbc_driver_flightsql.dbapi.connect(self.uri,db_kwargs=db_kwargs,autocommit=True,) -
Для HTTP:
curl --location-trusted -L -X POST -u tcs:tcs -H "x-tcs-route:rw" -d 'CREATE TABLE t(a int)' http://localhost:7780/sql
По умолчанию, ответы на запросы к TCS содержат массив данных без указания схемы. Например:
$ curl -u tcs:tcs -d 'insert into t values(1)' http://127.0.0.1:7777/sql{"responses":[{"is_success":true,"rows":[{"count":1}],"timings":{"collect":"494.295µs"}}]}%
При необходимости можно включить в ответ схему данных. Для этого в заголовке запроса нужно указать
параметр x-tcs-include-schema: true. Тогда в начале ответа возвращается схема данных в формате колонка:тип.
Причем схема данных включается в ответ, даже если возвращается 0 строк.
Например:
$ curl -u tcs:tcs -d 'insert into t values(1)' -H 'x-tcs-include-schema: true' http://127.0.0.1:7777/sql{"responses":[{"is_success":true,"schema":[{"name":"count","type":"UInt64"}],"rows":[{"count":1}],"timings":{"collect":"311.063µs"}}]}
TCS не накладывает ограничений на следующее:
- глубина вложенности подзапросов;
- количество таблиц\представлений, участвующих в запросе;
- количество полей данных в результате;
- количество подзапросов.
Разрешено использовать подзапросы, а также расчетные значения подзапросов в последующих подзапросах.
Текущая версия TCS не поддерживает работу с пользовательскими функциями/процедурами.
TCS поддерживает работу с индексами типа key-value.
На пустой таблице индексы key-value создаются пустыми и наполняются по мере вставки новых данных. Но если на момент создания индекса в таблице уже есть данные, то они будут автоматически проиндексированы.
Этот вид индексов работает только для запросов на равенство значений. Запросы на сравнение значений (больше/меньше) пока не поддерживаются.
См. CREATE INDEX.
См. DROP INDEX.
Для всех индексов key-value проводится автоматическая переиндексация по мере изменения данных в таблице. Принудительно перестраивать индексы вручную не требуется.
Первичный индекс задается при создании таблицы. Он может быть:
-
задан пользователем, например:
CREATE TABLE t(a int,b int,c int,PRIMARY KEY(a)) -
либо создан автоматически, например:
CREATE TABLE t(a int,b int,c int)Здесь в таблицу
tбудет автоматически добавлено полеrowid(оно станет первым полем в таблице), а по нему будет создан первичный индекс.
У таблицы может быть только один первичный индекс. Все остальные индексы в таблице являются вторичными.
Первичный индекс должен быть уникальным.
Он может строиться как по одному столбцу, так и по нескольким (см. составные индексы).
Вторичные индексы могут быть только неуникальными (задать UNIQUE для них в текущей версии TCS нельзя).
Они могут строиться как по одному столбцу, так и по нескольким (см. составные индексы).
Составной индекс может содержать более одного столбца.
Для создания составных KV-индексов поддерживаются запросы следующего вида:
-
первичный составной индекс:
CREATE TABLE t(a int,b int,c int,PRIMARY KEY(a, c)) -
вторичный составной индекс:
CREATE INDEX SYNC test_index ON departments(name, manager, size);
Чтение с использованием индекса осуществляется при наличии условия (в т.ч. сортировки) по первому или по нескольким полям индекса. Например:
SELECT * FROM departments WHERE name = 'HR' AND manager != 'Ivanov' ORDER BY size;
При создании составного индекса порядок столбцов может быть любой. При чтении по составному индексу для лучшей производительности рекомендовано придерживаться того же порядка столбцов, что был указан при создании индекса.
По умолчанию, все индексы в TCS создаются с возрастающим порядком сортировки.
Например, инструкция CREATE INDEX t(a,b,c) имеет тот же эффект, что и
CREATE INDEX t(a ASC, b ASC, c ASC).
При необходимости порядок сортировки для индекса, заданного пользователем
(как первичного, так и вторичного), можно задать с помощью ключевых слов desc
(убывающий порядок) и asc (возрастающий порядок).
Для составных индексов порядок сортировки можно задавать индивидуально для каждой компоненты.
Например:
-- первичный составной индексCREATE TABLE t(a int, b int, primary key(b DESC, a ASC))-- вторичный составной индексCREATE INDEX my_ind ON t(b DESC, a ASC)
Для первичного индекса, создаваемого автоматически (rowid), также можно явным образом
задать порядок сортировки. Например:
CREATE TABLE t(a int, primary key(rowid DESC))
Здесь выборка по первичному ключу вернет данные в порядке, обратном порядку их вставки.
Данные возвращаются в том порядке, который задан для индекса, по которому производится выборка. В частности, выборка по вторичному индексу может вернуть данные в ином порядке, чем выборка по первичному индексу. Например, если нужно читать данные в порядке, обратном вставке, но для таблицы не задан убывающий первичный ключ, то можно задать вторичный индекс с нужным порядком:
CREATE INDEX i ON t(a, rowid DESC)
В результате при чтении по индексу i данные будут предоставляться в порядке убывания rowid.
Также можно явно задавать порядок чтения по вторичному индексу, в состав которого
входит автоматически создаваемый первичный индекс (rowid). Например:
CREATE INDEX sec ON t(a, rowid desc)
Здесь записи в выборке по составному индексу a, rowid будут отсортированы
вначале по a (в убывающем порядке), а затем внутри одинаковых групп – по rowid
(в том порядке, который был указан при создании первичного индекса по rowid).
Порядок чтения ассоциирован с самим индексом, его нельзя менять. Для чтения в другом порядке нужно создавать новый индекс.
Для планировщика можно явно указать конкретный индекс (с заданным в этом индексе порядком чтения)
с помощью функции plan_with с аргументом use_index.
Индексы (и первичные, и вторичные) оптимизируют запросы с указанием равенства и диапазона значений.
Для эффективной работы фильтрующее выражение в запросе должно сначала задавать
условия равенства по первым компонентам индекса (если он составной), а затем – условия
вхождения в диапазон для последующей компоненты: col1=x1, col2=x2, ..., coln in [ln, rn]
Например, если индекс состоит из одной компоненты (a), то с его использованием
можно сделать запросы со следующими фильтрами:
a = 1a > 1a > 2 AND a < 3a < 3
Если индекс содержит две компоненты (a, b), то в запросе можно задать следующие фильтры:
a = 1 AND b > 2a = 1 AND b = 1a = 1 AND b > 3a > 1a > 1 AND a < 10
Индексы используются планировщиком:
-
при сканировании, например:
EXPLAIN SELECT * FROM t WHERE a = 1 AND c = 2----logical_plan TableScan: t projection=[a, b, c], full_filters=[t.a = Int32(1), t.c = Int32(2)]physical_plan01)IndexScanExec: table=tcs.public.t, index=pk_tcs_public_t, direct_projection=[a, b, c]02)--Range: (a = 1) AND (c = 2) -
при поиске по диапазону, например:
EXPLAIN SELECT * FROM t WHERE a > $1 AND a < $10----logical_plan TableScan: t projection=[a, b, c], full_filters=[t.a > $1, t.a < $10]physical_plan01)IndexScanExec: table=tcs.public.t, index=pk_tcs_public_t, direct_projection=[a, b, c]02)--Range: $1 < a < $10
IndexScanExec, единый узел плана выполнения для пользовательских таблиц в TCS,
сначала предпринимает попытку исполнить проекцию всех требуемых столбцов с помощью
первичного индекса, без сканирования всей таблицы.
Если это не удается, то предпринимаются дополнительные попытки поиска.
Таким образом, при сканировании исполняются проекции двух видов:
- прямая проекция – проводится только с использованием первичного индекса.
- косвенная проекция – проводится дополнительно для каждой записи с использованием вторичного индекса.
Косвенная проекция в среднем работает медленнее, поэтому планировщик пытается по возможности использовать первичные индексы.
В примерах выше ответ не содержит информацию о косвенных проекциях, поскольку там исполняются только прямые проекции (по первичному индексу). Рассмотрим пример запроса, где исполняются оба вида проекций:
CREATE TABLE t(a int, b int, c int)-- создаем вторичный индексCREATE INDEX SYNC ta ON t(a)EXPLAIN SELECT * FROM t WHERE a = 1----logical_plan TableScan: t projection=[a, b, c], full_filters=[t.a = Int32(1)]physical_plan01)IndexScanExec: table=tcs.public.t, index=ta, direct_projection=[a, rowid], indirect_projection=[b, c]02)--Range: a = 1
Здесь планировщик производит выборку по индексу ta.
Сначала он смог исполнить проекцию колонки a и rowid с помощью первичного индекса (прямая проекция).
А для колонок b и c пришлось построчно исполнить косвенные проекции.
Таким образом, единственной разницей в работе первичных и вторичных индексов является то, что первичный индекс позволяет исполнить проекцию всех столбцов из себя напрямую, в то время как вторичный индекс позволяет исполнить проекцию только тех столбцов, которые были явно указаны при его создании.
Вытеснение данных подразумевает удаление данных из БД, либо перемещение данных из оперативной памяти на диск с целью охлаждения данных.
Вытеснение данных из TCS выполняется автоматически по мере заполнения хранилища, либо по истечении времени хранения данных.
При добавлении новых записей сверх лимита одновременно хранимых записей наиболее старые записи удаляются.
Вытеснение данных по количеству записей организовано потаблично: для каждой таблицы может быть определен свой лимит количества одновременно хранимых записей.
Лимит задается с помощью параметра MAX_ROWS и указания максимального количества записей в таблице:
- при создании таблицы, например:
CREATE TABLE t MAX_ROWS 10000 - при изменении таблицы, например:
ALTER TABLE t MAX_ROWS 100000
В результате, самые старые записи, которые выходят за указанный лимит, будут удалены из таблицы.
По умолчанию, лимит для таблиц не установлен: без явного указания лимита MAX_ROWS при создании таблицы вытеснение данных из нее не производится.
При необходимости можно в дальнейшем отключить вытеснение, задав значение лимита равное 0, например:
ALTER TABLE t MAX_ROWS 0.
Вытеснение записей из таблиц производится только перед операциями вставки, чтобы не превысить установленный лимит.
При обнаружении данных, которые хранятся сверх указанного срока, все устаревшие данные удаляются или перемещаются на внешний том. Вытеснение (удаление или перемещение) происходит по расписанию, в фоновом режиме.
Вытеснение данных по времени организовано потаблично: для каждой таблицы могут быть определены свои условия.
Чтобы настроить вытеснение по времени для новой таблицы, нужно сделать вызов CREATE TABLE следующего вида:
CREATE TABLE table_name (id u64,created_at ts)[TTL exprDELETE | INTO VOLUME 'volume_name'SCHEDULE 'cron_expr']
где:
-
(Обязательно) Столбец типа
ts(например,created_at ts). По этому столбцу TCS создает вторичный индекс для быстрого поиска данных, подлежащих вытеснению. -
(Обязательно)
TTL expr– выражение, определяющее момент устаревания данных (например,created_at + INTERVAL 7 DAYS). Выражениеexprдолжно возвращать значение типаtsи имеет следующий формат:<timestamp_column> + INTERVAL <time_interval> <interval_type>где:
- (Обязательно)
<timestamp_column>– указанный выше столбец типаtsс временными метками; - (Oбязательно)
INTERVAL– длительность хранения относительно временной метки, состоящая из целочисленного значения<time_interval>и типа интервала<interval_type>(например, DAYS, MONTHS, YEARS, HOURS).
- (Обязательно)
-
(Обязательно) Действие по истечении TTL:
DELETE– удаление данныхINTO VOLUME 'volume'– перемещение данных на указанный внешний том
-
(Обязательно)
SCHEDULE– частота проверки и вытеснения данных. Задается с использованием синтаксиса планировщикаcrontab, например:'@hourly'(каждый час)'30 * * * *'(раз в 30 минут)
Настройка ежедневной проверки с помощью сокращений
'@daily'и@midnightне поддерживается. Вместо этого можно использовать выражение(0 0 * * *)(ежедневная проверка в полночь).
Пример 1: создание таблицы с вытеснением (удалением) данных старше 7 дней, с ежедневной проверкой.
CREATE TABLE my_table (id u64,created_at ts)TTL created_at + INTERVAL 7 DAYSDELETESCHEDULE '(0 0 * * *)'
Пример 2: создание таблицы с вытеснением (охлаждением) данных старше 7 дней на внешний том, с ежедневной проверкой.
CREATE TABLE my_table (id u64,created_at ts)TTL created_at + INTERVAL 7 DAYSINTO VOLUME 'my_volume'SCHEDULE '(0 0 * * *)'
В текущей версии TCS данная возможность не поддерживается.
"Охлаждение данных" подразумевает перенос данных из горячего хранилища (колоночного хранилища TCS в оперативной памяти), которое обеспечивает максимально быстрый доступ к данным, в холодное (хранилище, использующее дисковое пространство для хранения данных), когда данные устаревают. Это позволяет увеличить объем хранимых данных при ограниченном объеме оперативной памяти.
Возможности и ограничения текущей версии TCS:
- Охлаждение данных настраивается потаблично, с использованием механизма TTL (Time to Live), который обеспечивает автоматическое удаление или перемещение данных по истечении заданного времени. Охлаждение по количеству записей (объему) и по прочим условиям (например, по триггеру) не поддерживается.
- Настройка охлаждения доступна только для новых таблиц. Для уже существующих таблиц эта возможность не поддерживается.
- Поддержана работа с данными в формате Parquet и Iceberg.
- Не поддержаны некоторые типы данных: логический (bool), знаковые целочисленные до i32 (i16, i8) и все беззнаковые целочисленные (u64, u32, u16, u8).
- Охлаждение осуществляется только на локальный диск. Работа с хранилищами S3 не поддерживается. Также пока недоступно изменение существующего локального тома.
- Не поддержано партиционирование данных во внешнем хранилище (параметр PARTITION BY в запросах CREATE TABLE и ALTER TABLE).
- Охлаждение – однонаправленный процесс. После сброса на диск данные не возвращаются обратно в память.
- Данные на диске нельзя менять, в том числе и схему данных.
- Вставка данных всегда производится сначала в оперативную память, где данные накапливаются и охлаждаются в соответствии с выбранной стратегией.
- Метрики мониторинга для охлаждения данных пока недоступны.
- Охлаждение данных работает только в режиме проксирования. В режиме шардирования охлаждение не поддерживается.
Перед настройкой процесса охлаждения данных необходимо создать внешний том (external volume) -- специальное описание внешнего хранилища, куда будут вытесняться данные.
Для организации локального хранения используется команда следующего вида:
CREATE EXTERNAL VOLUME my_local_volume AS'/tmp/AAA'WITH ('format' = 'iceberg','db_file_name' = 'my-iceberg.catalog');
где:
-
(Обязательно) Путь к локальному хранилищу указывается без префикса
file://. -
(Обязательно) Блок
WITHсодержит следующие параметры:- (Обязательно)
format– формат хранения данных. Поддерживается только одно значение:iceberg. Тем не менее этот параметр является обязательным. - (Необязательно)
db_file_name– путь к тому вtcs_volumes_list()иDESCRIBE. В данном примере путь будет равен/tmp/AAA/my-iceberg.catalog. По умолчанию (если бы параметрdb_file_nameне был задан), путь бы равнялся/tmp/AAA/my_local_volume.
- (Обязательно)
Для получения общей информации о подключенных внешних томах используется следующая команда:
SELECT * from tcs_volumes_list()
Возвращаемые данные:
- имя внешнего тома
- формат данных
- идентификатор URI (путь хранения данных)
- количество таблиц, связанных с этим томом
Пример:
SELECT * from tcs_volumes_list() ORDER BY name----volume1 iceberg sqlite:///tmp/A/volume1 42volume2 iceberg sqlite:///tmp/B/volume2 10volume3 iceberg sqlite:///tmp/C/volume3 0
Для получения расширенной информации о настройках и характеристиках выбранного внешнего тома используется команда следующего вида:
DESCRIBE STORAGE_INTEGRATION my_volume
где:
- (Обязательно)
my_volume– имя внешнего тома.
Помимо общей информации, в ответе возвращается:
- имя набора реплик, который в случае формата Iceberg используется как пространство имен (namespace) для данных таблиц
- список связанных таблиц
- тип каталога
Пример:
DESCRIBE STORAGE_INTEGRATION volume1----volume1 iceberg sqlite:///tmp/A/volume1 replicaset1 [] local-sqlite
Для удаления внешнего тома используется команда следующего вида:
DROP EXTERNAL VOLUME [ IF EXISTS ] my_volume;
где:
- (Необязательно)
IF EXISTS– параметр, который предотвращает возникновение ошибки, если удаляемый том не существует. - (Обязательно)
my_volume– имя удаляемого внешнего тома.
При выполнении команды происходит полное удаление указанного внешнего тома, а также освобождение связанных с томом ресурсов и обновление системных записей.
При попытке удалить внешний том, который задействован в процессе охлаждения данных, TCS блокирует операцию удаления, формирует сообщение об ошибке и предоставляет полный список таблиц, зависящих от данного тома.
Для чтения определенного вида данных в рамках текущей сессии нужно установить переменную
tcs.volume_read_mode:
SET tcs.volume_read_mode = 'skip'– не читать данные с диска.SET tcs.volume_read_mode = 'fallback'(по умолчанию) – сначала пытаться читать данные из памяти, если там пусто – читать с диска.SET tcs.volume_read_mode = 'union'– читать данные параллельно и из памяти, и с диска.
См. Вытеснение данных по времени.
TCS поддерживает работу с общедоступными драйверами для интерфейсов JDBC и ADBC по SQL-протоколу Apache Arrow Flight.
Скачайте установочный пакет нужного драйвера по ссылке:
- JDBC: https://repo1.maven.org/maven2/org/apache/arrow/flight-sql-jdbc-driver
- ADBC: https://pypi.org/project/adbc-driver-flightsql/
-
В DBeaver добавьте драйвер JDBC для Arrow Flight SQL в качестве нового драйвера:
a. В меню выберите пункт Database > Driver Manager.
b. В диалоговом окне Driver manager нажмите Create.
c. В разделе Settings выполните следующие действия:
- В поле Name укажите имя драйвера, например
JDBC Driver for Arrow Flight SQL. - В поле Driver Type убедитесь, что выбран тип драйвера
Generic. - В поле Class Name укажите
org.apache.arrow.driver.jdbc.ArrowFlightJdbcDriver. - В поле URL Template укажите
jdbc:arrow-flight-sql://{host}:{port}(например,jdbc:arrow-flight-sql://localhost:50051). - В поле Default Port укажите порт
50051.
d. В разделе Libraries нажмите Add File и выберите .jar-файл для драйвера JDBC для Arrow Flight SQL.
e. Нажмите OK.
- В поле Name укажите имя драйвера, например
-
Создайте подключение к DBeaver, использующее ваш драйвер:
a. Выберите Database > New Connection from JDBC URL.
b. В поле Create New Connection в диалоговом окне JDBC URL введите
jdbc:arrow-flight-sql://{host}:{port}?useEncryption=0(например,jdbc:arrow-flight-sql://localhost:50051?useEncryption=0).Свойство
useEncryption=0(false) необходимо указывать явно, поскольку при работе с текущей версией TCS поддерживаются только незашифрованные JDBC-соединения. Значение по умолчанию для этого свойства равно1(true).В результате DBeaver добавит ваш драйвер в список Drivers.
c. Выберите ваш драйвер в списке Drivers и нажмите Next.
d. В диалоговом окне Connect to a Database укажите свои учетные данные для аутентификации. При работе с текущей версией TCS поддерживаются только JDBC-соединения по имени пользователя и паролю.
Учетные данные задаются в конфигурации TCS.
e. (необязательно) Нажмите Test Connection. Если подключение работает, откроется диалоговое окно Connection Test, в котором указывается, что DBeaver может подключиться к TCS. После попытки подключения соединение закрывается. Нажмите OK.
f. Нажмите Finish.
-
Склонируйте локально репозиторий Apache Superset https://github.com/apache/superset.
-
В локальном репозитории Apache Superset создайте файл
docker/requirements-local.txtи впишите в него пакеты с зависимостями:pyarrow==15.0.0flightsql-dbapi==0.2.2adbc-driver-flightsql==1.4.0psycopg2-binary==2.9.10 -
Соберите и запустите Docker-образ Apache Superset с помощью Docker Compose:
export TAG=4.1.1docker compose -f docker-compose-image-tag.yml upПодробнее см. https://superset.apache.org/docs/installation/docker-compose/.
-
Подключитесь к веб-интерфейсу Apache Superset по HTTP-адресу
http:/localhost:8088. -
Добавьте новое соединение
datafusion+flightsql://tcs:tcs@{host}:{port}?insecure=True(например,datafusion+flightsql://tcs:tcs@host.docker.internal:50051?insecure=True).Подробнее см. https://superset.apache.org/docs/configuration/databases#connecting-through-the-ui.
Параметры строки соединения для каждого драйвера описаны в документации Apache Arrow:
- JDBC: https://arrow.apache.org/docs/java/flight_sql_jdbc_driver.html
- ADBC: https://arrow.apache.org/adbc/current/python/api/adbc_driver_flightsql.html
Для работы с первичными индексами через JDBC доступна функция getPrimaryKeys(),
которая возвращает описания колонок всех первичных индексов для указанной таблицы.
См. подробнее в документации Oracle.
Драйвер ADBC, использующийся в текущей версии TCS, не поддерживает работу с индексами.
-
Создание SQL-представления: доступно через SQL-запрос.
-
Просмотр списка всех доступных SQL-представлений:
- В редакторе DBeaver: нажать кнопку
Refresh, все доступные SQL-представления отобразятся в спискеViews. - В редакторе Superset: нажать кнопку
Refresh, все доступные SQL-представления отобразятся в спискеTABLE.
- В редакторе DBeaver: нажать кнопку
-
Просмотр текста SQL-представления: в любом редакторе выбрать SQL-представление в списке, рядом отобразится его текст.
-
Замещение SQL-представления: доступно через SQL-запрос.
-
Удаление SQL-представления: доступно через SQL-запрос.
Подробнее про аналитическиа расчеты (prepared statements) в TCS см. в разделе .
Требуется JDBC-драйвер flight-sql-dbc-driver версии не ниже 18.3.0.
Для работы с этим драйвером нужно установить зависимость в клиентском приложении.
Пример: добавление зависимости в pom.xml:
<dependency><groupId>org.apache.arrow</groupId><artifactId>flight-sql-jdbc-driver</artifactId><version>18.3.0</version></dependency>
Пример: строка соединения:
jdbc:arrow-flight-sql://localhost:50051?useEncryption=false&user=tcs&password=tcs
Требуется драйвер go adbc версии не ниже 1.7.0.
Пример кода создания/вызова:
prepared, err := db.Prepare("SELECT * FROM t WHERE a=$1")if err != nil {log.Fatalf("Failed to prepare the statement: %v", err)}var num int32var str stringif err = prepared.QueryRow(1).Scan(&num, &str); err != nil {log.Fatalf("Failed to execute query: %v", err)}fmt.Println(num, str)
Пакетная загрузка данных через JDBC осуществляется с помощью вставки следующего вида:
INSERT INTO таблица (столбец1, столбец2) VALUES ($1, $2);
Пример кода:
static String singleRowPreparedInsert = "INSERT INTO t VALUES($1, $2, $3, $4)";static void runBatchInsert(Connection conn) throws SQLException {try (var statement = conn.prepareStatement(singleRowPreparedInsert)) {for (int i = 2; i <= 5; ++i) {statement.setInt(1, i);statement.setInt(2, i);statement.setString(3, String.format("%d", i));statement.setBoolean(4, true);statement.addBatch();}statement.executeBatch();}}
Порядок работы с сессиями в TCS разнится в зависимости от протокола.
Для протокола HTTP каждый запрос выполняется в отдельной сессии. Она автоматически открывается при получении запроса и закрывается по окончании обработки.
Для протокола Arrow Flight SQL сессию необходимо открывать явным образом с помощью запроса Handshake.
Сессия должна быть создана до отсылки всех SQL-запросов, которые будут осуществляться
в рамках этой сессии, в т.ч. запросов SET, с помощью которых можно задавать параметры сессии.
Закрытие сессии происходит по запросу CloseSession.
Также сессия закрывается автоматически по истечении макcимальной длительности сессии (параметр session_expiration_secs, по умолчанию – 8 часов).
Подробнее см. документацию Arrow Flight RPC и Arrow Flight SQL.
Поддерживаются стандартные функции синхронной/асинхронной репликации Tarantool.
TCS поддерживает горизонтальное масштабирование посредством механизма шардирования, что предполагает разбиение набора данных на части и распределение их по нескольким наборам реплик (шардам). Данные распределяются по шардам по ключу шардирования, который указывается для каждой шардированной таблицы.
Для запросов на чтение в режиме шардирования предусмотрены специальные оптимизации.
Ограничения текущей версии TCS:
-
При переходе на шардированную конфигурацию требуется полная перезаливка данных.
-
Режим шардирования (параметр
mode.sharded) не рекомендуется включать, если в конфигурации кластера не заданы хотя бы 2 шарда. -
Распределение данных между шардами осуществляется на основе актуальной конфигурации кластера. Любые изменения в конфигурации наборов реплик после начальной загрузки данных могут вызвать нарушения в работе механизма шардирования. К критическим изменениям относятся:
- Переименование существующих наборов реплик;
- Удаление наборов реплик;
- Добавление новых наборов реплик.
В случае проведения подобных операций после изменения конфигурации необходима полная перезаливка данных для обеспечения корректной работы системы шардирования.
Для создания шардированной таблицы используется команда с параметром SHARDED BY, где указывается ключ, по которому будет проводиться шардирование.
Ключ шардирования может быть строкой, числом или составным ключом.
При выборе ключа рекомендуется руководствоваться несколькими принципами:
- запросы должны быть максимально локализованы;
- данные должны быть сбалансированы по ключу.
Пример: создание шардированной таблицы с составным ключом
CREATE TABLE t(a i32,b utf8,c u64,d bool)SHARDED BY a, b
Шардированные таблицы можно создавать, только если кластер работает в режиме шардирования.
Как и все прочие запросы к кластеру в режиме шардирования, запросы на создание таблицы следует отправлять через экземпляр Scheduler, а не напрямую через экземпляр Storage.