
Данные стали новой нефтью. Сегодня любой бизнес-процесс, любую сущность можно свести к набору данных о нем и соответствующим образом выстроить свою систему для работы с этими объектами. Однако для того, чтобы извлечь из этой нефти пользу, нужны программные системы, которые не просто умеют ее качать, но обрабатывать, хранить и делать это быстро, безопасно и отказоустойчиво. Программные системы, которые ставят данные во главу угла, предоставляя так необходимый 360 градусный обзор для сегодняшнего бизнеса, нужный для быстрого развития и оперативной реакции на бизнес-события. Мы изучили тему и делимся трендами разработки, которые прямым образом влияют на более эффективную работу с данными.
Облако
Облако популяризировало модель предоставления ресурсов в виде сервисов. Использование облачных баз данных как сервиса либо размещение баз данных на облачных ресурсах (виртуальных машинах, реже контейнерах) позволило рассматривать переход с модели CAPEX на OPEХ. В 2022 этот нарратив постепенно начал уступать другому важному нюансу - облачные инструменты ускоряют процессы бизнес-трансформации внутри компаний, в немалой степени за счет того, что выделение ресурсов и их использование гораздо гибче, соответственно, человеческие силы перераспределяются на более важные задачи, при этом ускоряется запуск новых систем и бизнес-сервисов. Базы данных и хранилища являются одними из самых популярных сервисов в облаке и этот тренд ожидается к росту в 2023, так как характеристики именно облачных платформ и сервисов позволили перейти на качественно иной уровень работы с данными.
Искусственный интеллект
Благодаря дешевым производительным ресурсам и общему развитию “железной” индустрии применение искусственного интеллекта в задачах обработки данных вышло на уровень, на котором его теперь может использовать любая компания. Облачные провайдеры, такие как Google и Oracle, добавляют API-compatible реализации MySQL и PostgreSQL, в которых рядом с обработкой транзакций и аналитикой рможет работать AutoML. В 2023 мы ожидаем увидеть увеличение практических приложений AI в базах данных (автоматическая настройка и оптимизация, рекомендации) и аналитических инструментах. Для того, чтобы получать ответы из данных быстрее.
Интеграция и опыт разработчика
Современные подходы к управлению данными подразумевают, что эти данные проходят через определенную последовательность операций - через сбор, трансформацию, работу с data warehouse и визуализацию и аналитику. Этот стек называют современным стеком работы с данными (Modern Data Stack). Современным этот стек называется из-за активного использования облачных платформ. Облачная платформа берёт на себя задачи по поддержке и обновлению компонентов стека, масштабированию.
Побочный эффект в том, что инструментов стало настолько много, что интегрировать их в некоторых случаях стало сложнее. Каждый из инструментов делает жизнь разработчика проще, но собрать стек с использованием added-value сервисов (таких, как искусственный интеллект) не основываясь только на собственных скиллах и любимых сервисах все сложнее.Ожидаем, что в 2023 начнёт происходить больше общения и больше интеграций. Kubernetes, о котором все больше говорят в контексте данных, объявил свежий релиз Electrifying и посвятил его работе над экосистемной интеграцией в том числе потому что инструментов достаточно, но работают они друг с другом не всегда очевидным образом.
Как практическое следствие этого, ожидаем увидеть автоматизацию задач по разработке и обработке данных (операционализации data-пайплайнов, когда происходит конвертация скриптов в Apache Airflow). Также эксперименты с архитектурой ожидаются в виде освоения serverless-архитектуры - отвязывании баз данных и разработки от низлежащих ресурсов (хранилища и серверных) в еще большей степени, нежели PaaS. Например, AWS добавили в свое портфолио serverless AI в виде OpenSearch, Oracle MySQL Heatwave и Google AlloyDB. Все это должно упростить как процессы разработки, так и в целом операционные и капитальные издержки бизнеса. Разумеется, serverless не является серебряной пулей, так как часто нагрузки должны быть стабильнее и предсказуемее и выбор остановится на зарезервированных классических мощностях, но для проверки гипотез или быстрого запуска продукта serverless может стать отличным выбором.
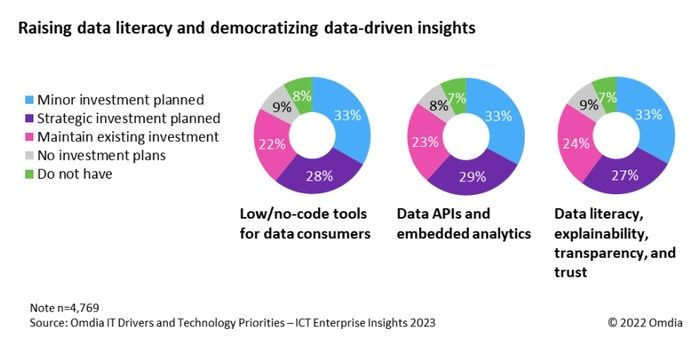
Платформизация
В конце 2022 года Гартнер определил 2025 как год, к которому 70% новых приложений будет разработано с использованием low-code/no-code подхода, а платформы будут помогать компаниях в высвобождении трудовых ресурсов и выходе на инновации.
Происходит это как по причине накопления внутренних инструментов и необходимости снизить когнитивную нагрузку у их пользователей, предлагая их через одно окно, так и необходимости постепенно приводить их к единому знаменателю. Не всегда эти инструменты работают друг с другом, а когда работают, то не всегда делают это удовлетворительно. Часты ситуации, когда одна legacy база данных замедляет обработку данных. В этом случае преимущества искусственного интеллекта и других инструментов, которым требуется отдавать данные, могут быть нивелированы и сценарии, в которых они работают (быстрая реакция на пользовательские тренды), не реализуются.
В будущем году ожидаем возникновения большего количества внутренних и внешних платформ, позволяющих управлять состоянием данных, делать Self-service аналитику и гибридные решения (связывающие несколько корпоративных периметров).
При этом мы не ожидаем массового ухода от классических отдельных разработок для транзакционных баз данных, data warehouses и других инструментов. Но в облаках наверняка возникнут новые интересные интеграции и варианты (например, как в Google Cloud AlloyDB, BigQuery и Dataproc разделяют общее хранилище, что удобно).
Операционализация
Операционализация в данном контексте является созданием системного подхода к автоматизации процессов и приведении их ближе к бизнес-показателям. Так, мы ожидаем, что в 2023 компании будут обращать больше внимания на метаданные своих данных, пытаясь изучить их не только на прикладном уровне, но и повысить их видимость среди пользователей в компании.
Вторая важная проблема, которая также будет решаться в 2023, это обнаруживаемость (observability), обеспечение качества и точности данных вместе с безопасностью. Данные должны быть не только созданы, переданы и проанализированы, но и приведены к регламентам, исследованы службой безопасности, желательно в автоматическом виде. Обеспечение обнаруживаемости и бОльшего использования данных стимулирует компании использовать подход DataOps. По аналогии с DevOps, DataOps призван за счет уже имеющихся практик (CI/CD, мониторинг, развертывание, тестирование) автоматизировать задачи внутри жизненного цикла данных и максимально рано обнаружить аномалии либо сбои.
Data Mesh
Data mesh - это подход к управлению данными, который основывается на идеях децентрализации и самоорганизации. В рамках этого подхода данные рассматриваются как продукт, который создают и потребляют различные команды внутри организации. Каждая команда отвечает за свои данные и обеспечивает их качество и доступность для других команд. Это позволяет ускорить процесс разработки и доставки продуктов, а также повысить гибкость и масштабируемость системы управления данными.
Data mesh уже много лет волнует индустрию, так как, в общем-то, объединяет в себе большинство остальных трендов и становится мета-трендом. Данные продолжают скапливаться в облачных и локальных хранилищах, компании ищут способы оптимизировать это хранение и наладить обнаружение некорректных данных. Это необходимо делать, так как при разделении обязанностей при отсутствии правильного контроля все это ведет к созданию data silos.
Тренд data mesh становится уже не столько технологическим, сколько организационным, культурным. Поэтому в 2023 и далее ожидаем развитие внутрикорпоративных дискуссий и поиска новых решений data fabric, backbone для метаданных.
Остались вопросы?
Расскажите о ваших задачах и узнайте больше
о реализации на платформе Tarantool