
Скорость доступа к данным влияет на быстродействие всей ИТ-системы. И, если система не подразумевает мгновенную обработку информации, то к архитектуре и ее компонентам обычно нет больших требований по скорости. Но когда система должна принять данные, обработать их и сформировать ответ за доли секунды, требования к скорости возрастают многократно. И этим требованиям каким-то образом нужно соответствовать.
Разбираемся, когда критически важна максимальная скорость доступа к данным и как ее обеспечить.
«Терпеть не стоит, ускорять» или «терпеть, не стоит ускорять»
Любой ИТ-продукт так или иначе работает с данными. Но профили нагрузок и требования к системам в разных сценариях отличаются. Например, пользователи готовы подождать, пока будет отрисован график для презентации, пока приложение банка сформирует отчет о расходах за 5 лет или сервис найдет самый дешевый билет на курорт. Такие операции не имеют критического значения, и ожидание даже в десять секунд вполне допустимо.
Вместе с тем, есть кейсы, когда обработка данных должна выполняться «на лету», а пользователям (или системе) нужен мгновенный результат. Например, к недопустимым можно отнести задержки при:
- печати чеков;
- верификации оплаты услуг;
- аутентификации;
- просмотре банковских операций и баланса;
- подготовке профиля клиента в колл-центре и не только.
Одновременно с этим, скорость обработки данных и доступа к ним важна не только в задачах, которые напрямую связаны со взаимодействием с пользователями. Так, возможность мгновенно запросить и обработать данные, а после сразу принять решение, нужны при:
- защите от всех видов мошенничества (antifraud);
- сборе телеметрии с оборудования (станков, датчиков, приборов);
- машинном обучении;
- работе с видеопотоком (например, в системах распознавания лиц на проходных офисов и заводов);
- управлении электротранспортом и автономными функциями современных автомобильных систем.
В каждом из этих и еще десятках других сценариев задержки влияют на пользовательский опыт, лояльность аудитории, безопасность, бизнес-процессы и в результате сказываются на репутации и успешности компании.
Варианты хранения данных: ищем самый «быстрый»
Для хранения данных в ИТ-системах можно задействовать:
- процессор (может хранить кэш данных);
- оперативную память;
- диски;
- ленты.
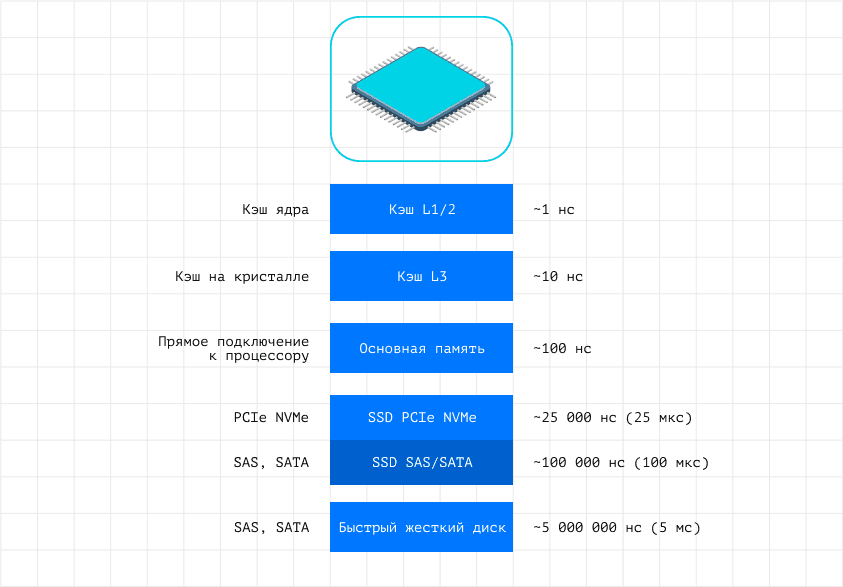
В контексте обеспечения быстрого доступа к данным, ленты — явно не лучший вариант. Во-первых, они изначально медленные. Во-вторых, они не подходят, когда нужно получить доступ к произвольным данным.
Самый «быстрый» компонент для хранения — кэш процессора. То есть, если нужна самая быстрая база данных — нужно задействовать кэш процессора.
Далее в топе по скорости среди хранилищ — оперативная память. У нее скорость доступа к данным ниже, чем в кэше процессора, но все равно кратно выше, чем у твердотельных накопителей и, тем более, классических жестких дисков.
Соответственно, диски не могут обеспечить такую же скорость доступа к данным, как оперативная память или кэш.
Но здесь есть нюансы:
- кэши процессора ограничены в размерах;
- данные в оперативной памяти могут быть утеряны в случае сбоя оборудования (например, если - выключат свет);
- диски медленнее, но надежнее и вместительнее других вариантов.
Ситуацию можно сравнить с выбором транспорта для перевозки грузов:
- самолет — быстро, но малая грузоподъемность,
- поезд — универсальное решение, но хочется быстрее,
- корабль — медленно, только по воде, но с огромной вместимостью.
Что в итоге
Оптимальный вариант организации хранения, позволяющий работать с нужными данными на максимальной скорости, — сочетание преимуществ нескольких компонентов и вариантов. И чтобы такое хранение было целесообразным по вместительности, надежности и стоимости, зачастую сочетают хранение на дисках и в оперативной памяти.
Вариантов организации хранения в такой «связке» два.
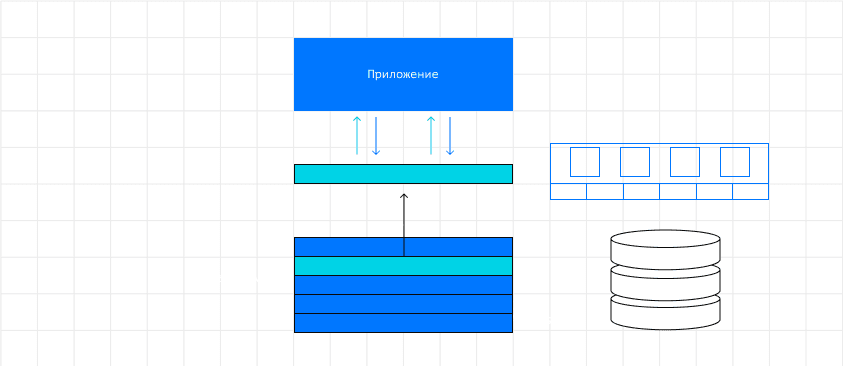
- Хранить всю базу на медленных накопителях, и только «горячие» данные и индексы - в ОЗУ. Например, можно часть данных и служебную информацию хранить в памяти, а основной массив данных — на дисках. Также в памяти можно закэшировать часть данных, которые запрашивают часто. При этом, если работать нужно со всем массивом хранящихся данных, обеспечивать одинаково высокую скорость доступа к ним не получится.
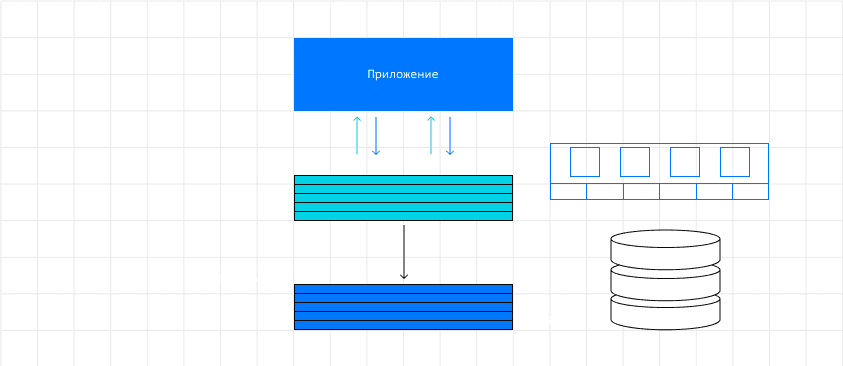
- Хранить все данные в ОЗУ, а на диск делать копию, чтобы не потерять, если что-то пойдет не так. Оперативная память вмещает меньше информации, чем диск, но при этом доступен максимально быстрый поиск данных в базе данных. Создание копии на диск позволяет минимизировать риски потери данные в случае сбоя на стороне оборудования.
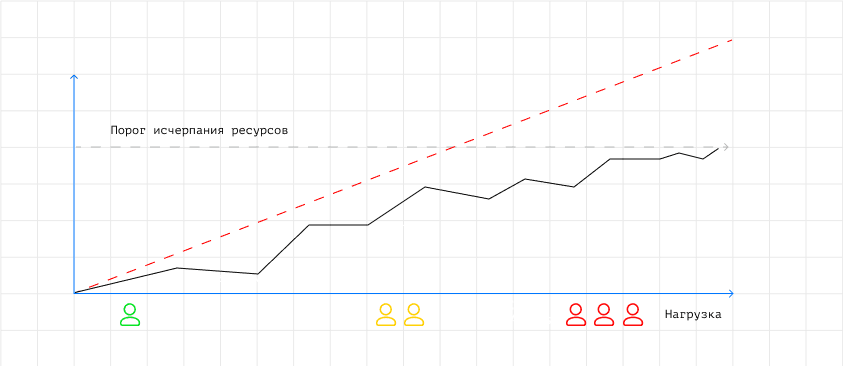
Важно еще понимать, что постоянное линейное вертикальное масштабирование хранилищ невозможно — есть порог исчерпания ресурсов. Соответственно, чтобы обойти эти ограничения, нужно отдавать предпочтение разработке высоконагруженных систем с горизонтальным масштабированием.
Таким образом, приоритетной моделью хранения для систем, где нужен мгновенный доступ к данным, является именно вариант с хранением всей информации в оперативной памяти, то есть резидентные СУБД.
Требования к хранилищу
В решениях, где скорость доступа к данным имеет критическое значение, важна не только модель хранения, выбранные носители и инфраструктура высоконагруженной системы, но и другие параметры — например, надежность, отказоустойчивость, управляемость.
Соответственно, помимо нужной комбинации носителей (оперативная память в сочетании с дисками), искомое хранилище должно соответствовать ряду требований:
- Последовательное выполнение операций (сериализуемость) — в таком случае не будет конкурентного доступа к данным, то есть процессы не будут мешать друг другу и «тормозить» отклик.
- Протоколирование операций на диск — гарантирует сохранение данных даже в случае сбоев.
- Реплицирование данных между несколькими узлами — повышает надежность и обеспечивает возможность работы с данными без простоя даже в моменты недоступности основного хранилища.
- Горизонтальное масштабирование или шардирование — чтобы выйти за ограничения физической инфраструктуры (серверов) по производительности, объему оперативной памяти и др.
- Встроенный язык программирования — чтобы можно было обрабатывать, анализировать и управлять данными непосредственно там, где они хранятся.
Такую комбинацию архитектуры, параметров и функций у себя «под капотом» сочетает Tarantool — технологическая платформа для построения решений по хранению данных.
Who is Mr. Tarantool
Tarantool объединяет экосистему продуктов для хранения данных разных типов и работы с ними. «Ядром» платформы является Tarantool Enterprise Edition — версия Tarantool, ориентированная на крупных клиентов, желающих построить нестандартные решения. Решение представляет собой основу для построения «умного» кэша и единого профиля клиента. Хранит комплексные типы данных с индексами и отношениями. При необходимости Tarantool позволяет использовать встроенный сервер приложений для реализации специфических сценариев обработки данных.
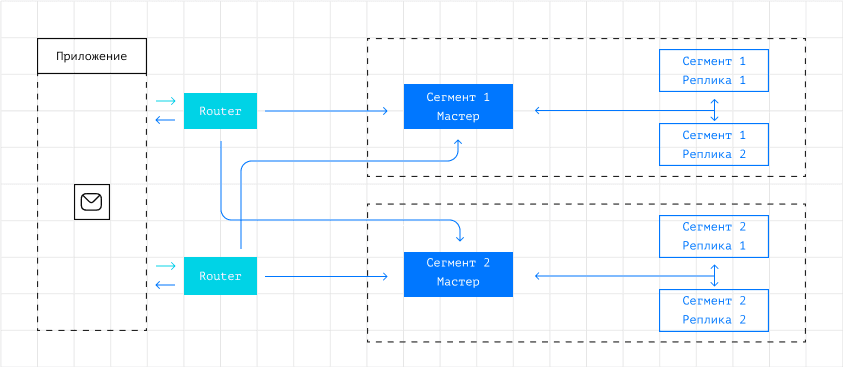
Tarantool предоставляет ряд преимуществ. Среди них:
- Высокая производительность благодаря in-memory технологиям.
- Отказоустойчивость распределенных хранилищ данных.
- Гарантия сохранности данных.
- Удобная установка и настройка кластера за счет интеграции с инструментами CI/CD.
- Удобная работа с хранилищем данных из бизнес-приложений.
- Поддержка от российского вендора. Соответствие требованиям ФСТЭК и наличие в реестре российского ПО.
Таким образом, Tarantool — универсальный инструмент, который может стать заменой для многих продуктов в используемых системах хранения.
Решения экосистемы Tarantool
Помимо платформы, в экосистеме Tarantool доступны коробочные инструменты, позволяющие быстро создать и настроить типовые сценарии для хранения и обработки данных.
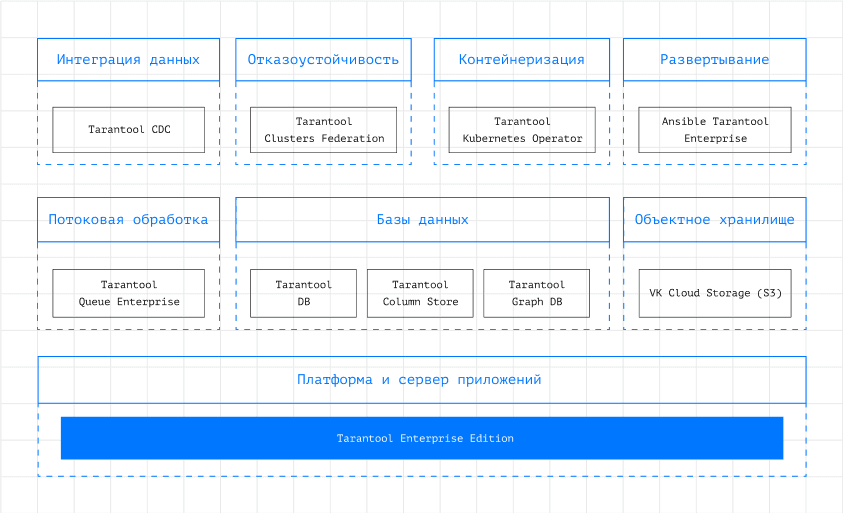
Среди них:
- Tarantool DB. Мультипротокольная NoSQL СУБД на основе Tarantool Enterprise Edition. Подходит для проектирования и разработки высоконагруженных информационных систем, а именно высокоскоростных отказоустойчивых транзакционных хранилища данных. В июне 2024 года СУБД включена в Реестр российского ПО.
- Tarantool Queue Enterprise. Инструмент для быстрого создания очередей на базе in-memory платформы Tarantool Enterprise Edition. Подходит для передачи сообщений между компонентами распределенных приложений, потоковой передачи данных в режиме реального времени и других высоконагруженных систем. Решение позволяет использовать два варианта архитектур: SQ — классические очереди с возможностью настройки приоритетов, MQ — распределенные системы очередей со строгим порядком обработки событий. Tarantool Queue Enterprise можно применять в сценариях, где нужны: транспорт между микросервисами, real-time marketing, управление задачами, маршрутизация и балансировка, решения на базе cобытийно-ориентированной архитектуры, обработка заказов и не только.
- Tarantool Column Store. Колоночная транзакционно-аналитическая БД на основе Tarantool Enterprise Edition. Подходит для проектирования высоконагруженных систем для анализа данных в реальном времени. Подходит для применения в системах, которые решают задачи антифрода (защиты от мошенничества), real-time формирования отчетности, real-time marketing, BI, AI/ML, систем рекомендаций, кредитного скоринга.
- Tarantool Graph DB. Графово-векторная БД на основе Tarantool Enterprise Edition. Позволяет создавать высокоскоростные хранилища графов для анализа данных в реальном времени.
Решение адаптировано под системы антифрода, геосервисы, маркетинг реального времени, AI/ML, системы рекомендаций, кредитный скоринг и другие сценарии применения.
Выводы
Постепенно скорость доступа к данным и возможность их обработки «на лету» становится не преимуществом, а критической необходимостью. Особенно в системах, где контакт с пользователем кратковременный и принять решение или сформировать персональное предложение нужно «здесь и сейчас».
Чтобы обеспечить максимальную скорость работы с данными, нужен комплексный подход — как на уровне выбора архитектуры высоконагруженных систем и носителей «под капотом», так и на уровне реализации алгоритмов обработки запросов. То есть нужно хранилище, которое сочетает все соответствующие практики и параметры. И таким решением могут быть продукты экосистемы Tarantool.
Остались вопросы?
Расскажите о ваших задачах и узнайте больше
о реализации на платформе Tarantool
Читайте также

Middleware для IoT и цифровых двойников

Выбор хранилища S3 On-Premises: анализ вариантов в РФ
