

Начало знакомства
Это рекомендованное руководство для знакомства с продуктом.
Примечание
Вам может понадобиться ознакомиться с базовым руководством по Tarantool. В нем запускается один экземпляр Tarantool, создается спейс, индекс и записываются данные.
Мы советуем новичкам сначала пройти текущее руководство, а затем вернуться к базовому для более глубокого погружения в продукт.
Если вы хотите быстро запустить готовый код, перейдите в раздел Запуск приложения.
Запуск в облаке
Данное руководство можно пройти в облаке. Это бесплатный и самый быстрый способ начать знакомство. Переходите на сайт try.tarantool.io и проходите этот туториал в облаке.
Однако для дальнейшего знакомства все же будет необходимо установить Tarantool.
Локальный запуск
Для пользователей Linux/macOS:
Установите Tarantool со страницы установки.
Install Node.js, which is required for the tutorial frontend.
Установите через ваш пакетный менеджер утилиту
cartridge-cli:sudo yum install cartridge-cli
brew install cartridge-cli
Подробности о том, как установить
cartridge-cli, читайте в руководстве по установке.Склонируйте репозиторий пошагового руководства.
В этом репозитории все готово к работе — в папке со склонированным примером выполните:
cartridge build cartridge start
Примечание
In case of a problem with cartridge build, run it with the --verbose flag
to learn about the source of the problem. If there is a problem with Node.js (npm):
- Check that Node.js is in the
$PATH. - Try forcefully removing the
node_modulesdirectory from the dependencies“ directories:
rm -rf analytics/node_modules front/node_modules
After that, try running cartridge build again.
If all else fails, please file us an issue on GitHub.
Готово! По адресу http://localhost:8081 вы увидите UI Tarantool Cartridge.
Запуск в Docker:
docker run -p 3301:3301 -p 8081:8081 tarantool/getting-started
Готово! По адресу http://localhost:8081 вы увидите UI Tarantool Cartridge.
Для пользователей Windows:
Используйте Docker и читайте раздел выше.
Сегодня мы решим высоконагруженную задачку для сервиса TikTok с помощью Tarantool.
У такого сервиса обычно самая нагруженная часть — это сохранение лайков под видео. Нужно будет создать базовые таблицы, индексы для поиска и в конце поднять HTTP API для мобильных клиентов.
Вам не потребуется писать дополнительный код. Все будет реализовано на платформе Tarantool.
Если по ходу выполнения инструкции вы случайно сделали что-то не то, есть волшебная кнопка, которая поможет вам сбросить все изменения. Она называется «Reset Configuration» и находится на вкладке «Cluster» в верхней части страницы.
Все, что нужно знать для старта:
В кластере Tarantool есть две служебные роли: router, storage.
- Storage — это хранилище данных.
- Router — это посредник между клиентами и storage. Он принимает запросы от клиентов, ходит к нужным экземплярам storage за данными и возвращает данные клиенту.
На вкладке «Cluster» мы видим, что в нашем распоряжении есть 5 несконфигурированных экземпляров.
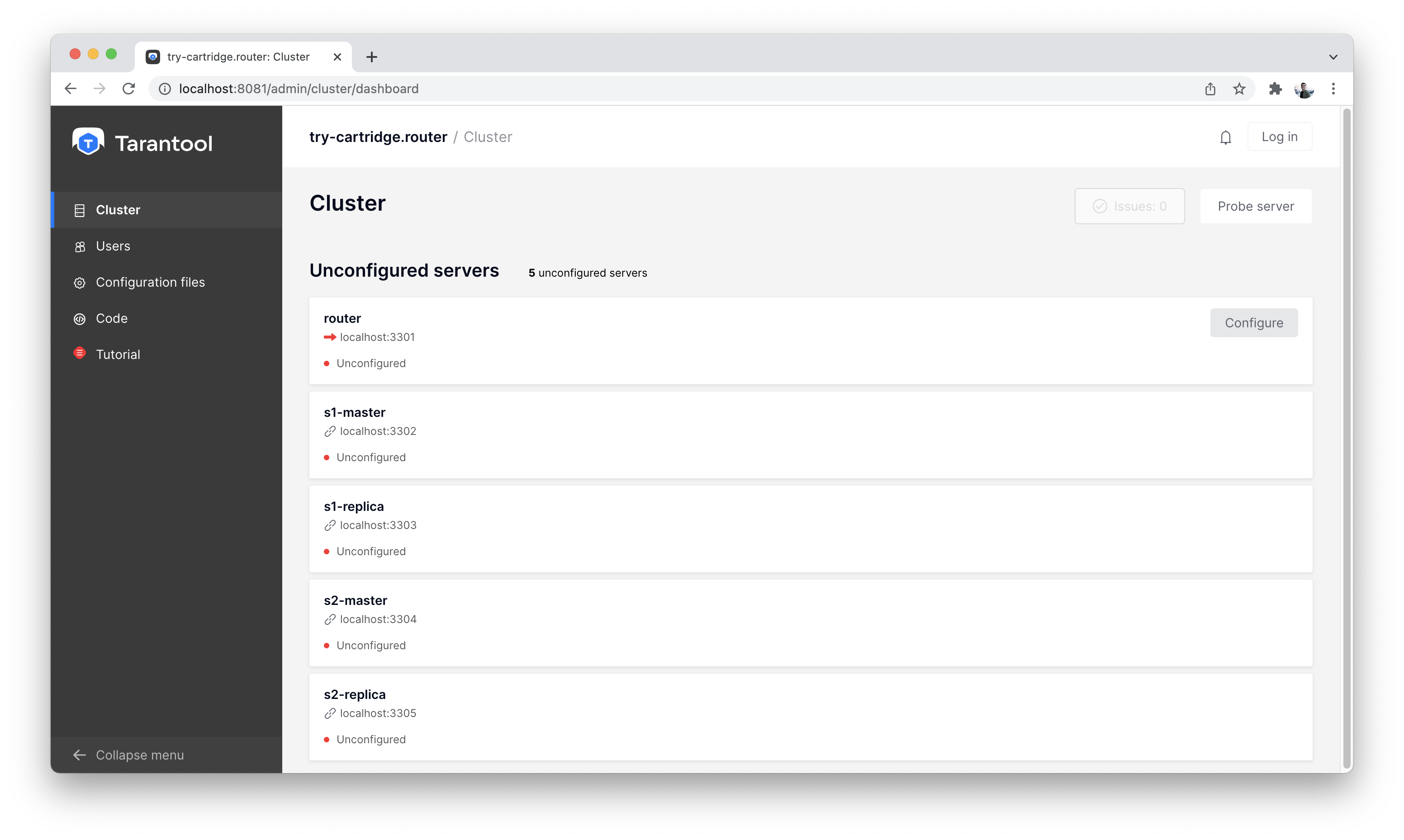
Список всех узлов
Создадим для начала один router и один storage.
Сначала нажимаем кнопку «Configure» на экземпляре «router» и настраиваем его как на скриншоте ниже:
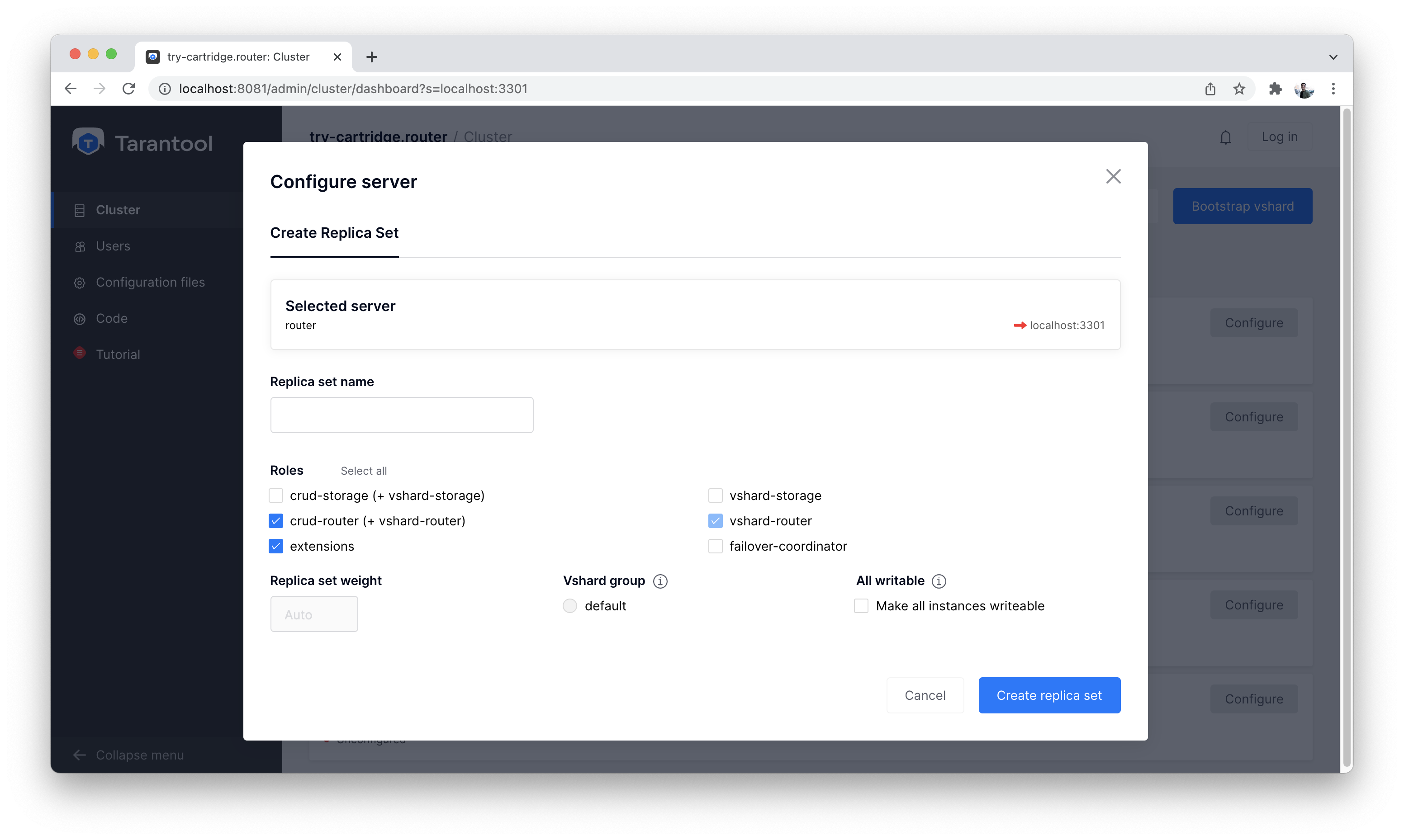
Настраиваем router
Далее настраиваем экземпляр «s1-master»:
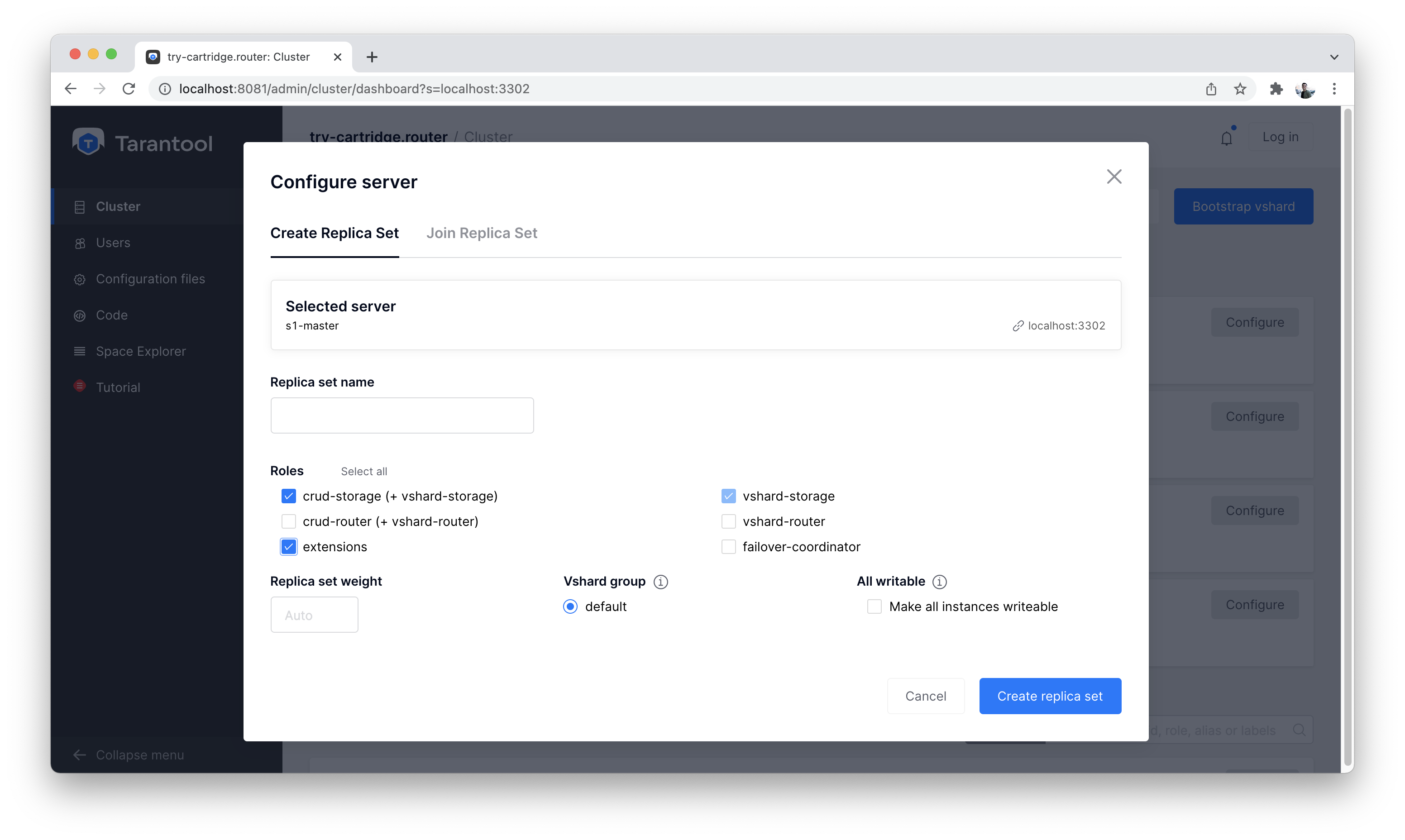
Настраиваем s1-master
Получится примерно вот так:
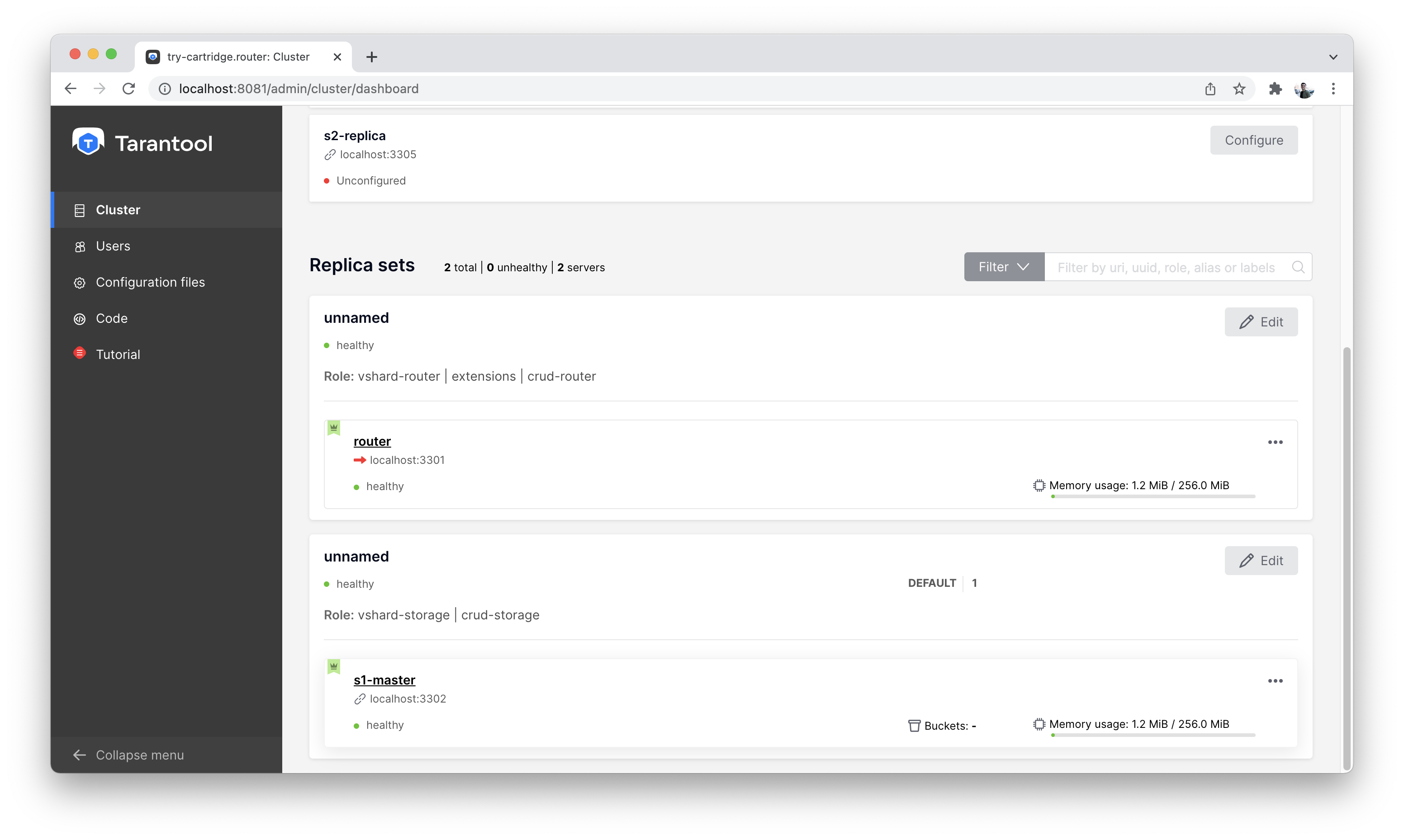
Вид кластера после первой настройки
Включим шардирование в кластере с помощью кнопки «Bootstrap vshard». Она находится справа сверху.
Let’s start with the data schema – take a look at the Code tab on the left.
There you can find a file called schema.yml. In this file, you can
describe the entire cluster’s data schema, edit the current schema,
validate its correctness, and apply it to the whole cluster.
Создадим необходимые таблицы. В Tarantool они называются спейсами (space).
Нам понадобится хранить:
- пользователей;
- видео с описаниями;
- лайки для каждого видео.
Copy the schema description from the code block below and paste it in the schema.yml file on the Code tab.
Click the «Apply» button.
After that, the data schema will be described in the cluster.
Вот как будет выглядеть наша схема данных:
spaces: users: engine: memtx is_local: false temporary: false sharding_key: - "user_id" format: - {name: bucket_id, type: unsigned, is_nullable: false} - {name: user_id, type: uuid, is_nullable: false} - {name: fullname, type: string, is_nullable: false} indexes: - name: user_id unique: true parts: [{path: user_id, type: uuid, is_nullable: false}] type: HASH - name: bucket_id unique: false parts: [{path: bucket_id, type: unsigned, is_nullable: false}] type: TREE videos: engine: memtx is_local: false temporary: false sharding_key: - "video_id" format: - {name: bucket_id, type: unsigned, is_nullable: false} - {name: video_id, type: uuid, is_nullable: false} - {name: description, type: string, is_nullable: true} indexes: - name: video_id unique: true parts: [{path: video_id, type: uuid, is_nullable: false}] type: HASH - name: bucket_id unique: false parts: [{path: bucket_id, type: unsigned, is_nullable: false}] type: TREE likes: engine: memtx is_local: false temporary: false sharding_key: - "video_id" format: - {name: bucket_id, type: unsigned, is_nullable: false} - {name: like_id, type: uuid, is_nullable: false} - {name: user_id, type: uuid, is_nullable: false} - {name: video_id, type: uuid, is_nullable: false} - {name: timestamp, type: string, is_nullable: true} indexes: - name: like_id unique: true parts: [{path: like_id, type: uuid, is_nullable: false}] type: HASH - name: bucket_id unique: false parts: [{path: bucket_id, type: unsigned, is_nullable: false}] type: TREE
Тут все просто. Рассмотрим важные моменты.
В Tarantool есть два встроенных движка хранения: memtx и vinyl. Первый хранит все данные в оперативной памяти, при этом асинхронно записывая на диск, чтобы ничего не потерялось.
Второй движок Vinyl — это классический движок для хранения данных на жестком диске. Он оптимизирован для большого количества операций записи данных.
Для сервиса TikTok актуально большое количество одновременных чтений и записей: пользователи смотрят видео, ставят им лайки и комментируют их. Поэтому используем memtx.
Мы указали в конфигурации три спейса (таблицы) в memtx и для каждого из спейсов задали необходимые индексы.
Их два для каждого спейса:
- Первый — это первичный ключ. Он необходим для того, чтобы читать/писать данные.
- Второй — это индекс для поля
bucket_id. Это поле служебное и используется при шардировании.
Важно: название bucket_id — зарезервированное. Если вы выберите другое название, то шардирование для этого спейса работать не будет. Если в проекте шардирование не используется, то второй индекс можно убрать.
Чтобы понять, по какому полю шардировать данные, Tarantool использует sharding_key. sharding_key указывает на поле в спейсе, по которому будут шардироваться записи. Таких полей может быть и несколько. В данном примере мы будем использовать только одно поле. Tarantool возьмет хеш от этого поля при вставке, вычислит номер бакета и подберет для записи нужный storage.
Да, бакеты могут повторяться, а каждый storage хранит определенный диапазон бакетов.
Еще пара мелочей для любопытных:
- Поле
partsв описании индекса может содержать несколько полей для того, чтобы построить составной индекс. В данной задаче он не требуется. - Tarantool не поддерживает Foreign key или «внешний ключ», поэтому в спейсе
likesнужно при вставке вручную проверять, что такиеvideo_idиuser_idсуществуют.
Записывать данные в кластер Tarantool будем с помощью модуля CRUD. Этот модуль сам определяет, с какого шарда читать и на какой шард записывать, и делает это за вас.
Важно: все операции по кластеру необходимо производить только на экземпляре router и с помощью модуля CRUD.
Подключим модуль CRUD в коде и напишем три процедуры:
- создание пользователя;
- добавление видео;
- лайк видео.
Процедуры нужно описать в специальном файле. Для этого перейдите на вкладку «Code». Создайте новую директорию под названием extensions, а в ней создайте файл api.lua.
Вставьте в этот файл следующий код, а затем нажмите «Apply».
local cartridge = require('cartridge')
local crud = require('crud')
local uuid = require('uuid')
local json = require('json')
function add_user(request)
local fullname = request:post_param("fullname")
local result, err = crud.insert_object('users', {user_id = uuid.new(), fullname = fullname})
if err ~= nil then
return {body = json.encode({status = "Error!", error = err}), status = 500}
end
return {body = json.encode({status = "Success!", result = result}), status = 200}
end
function add_video(request)
local description = request:post_param("description")
local result, err = crud.insert_object('videos', {video_id = uuid.new(), description = description})
if err ~= nil then
return {body = json.encode({status = "Error!", error = err}), status = 500}
end
return {body = json.encode({status = "Success!", result = result}), status = 200}
end
function like_video(request)
local video_id = request:post_param("video_id")
local user_id = request:post_param("user_id")
local result, err = crud.insert_object('likes', {like_id = uuid.new(),
video_id = uuid.fromstr(video_id),
user_id = uuid.fromstr(user_id)})
if err ~= nil then
return {body = json.encode({status = "Error!", error = err}), status = 500}
end
return {body = json.encode({status = "Success!", result = result}), status = 200}
end
return {
add_user = add_user,
add_video = add_video,
like_video = like_video,
}
Клиенты будут ходить в кластер Tarantool по протоколу HTTP. В кластере уже есть свой встроенный HTTP-сервер.
Чтобы сконфигурировать HTTP-пути, необходимо написать конфигурационный файл. Для этого перейдите на вкладку «Code». Создайте файл config.yml в директории extensions (вы ее создали на прошлом шаге).
Вставьте в этот файл следующий пример конфигурации и нажмите на кнопку «Apply».
---
functions:
add_user:
module: extensions.api
handler: add_user
events:
- http: {path: "/add_user", method: POST}
add_video:
module: extensions.api
handler: add_video
events:
- http: {path: "/add_video", method: POST}
like_video:
module: extensions.api
handler: like_video
events:
- http: {path: "/like_video", method: POST}
...
Done! Let’s make test requests from the console.
curl -X POST --data "fullname=Taran Tool" url/add_user
Примечание
In the requests, substitute url with the address of your sandbox.
The protocol must be strictly HTTP.
For example, if you’re following this tutorial with Try Tarantool, this request will look something like this (note that your hash is different):
curl -X POST --data "fullname=Taran Tool" http://artpjcvnmwctc4qppejgf57.try.tarantool.io/add_user
But if you’ve bootstrapped Tarantool locally, the request will look as follows:
curl -X POST --data "fullname=Taran Tool" http://localhost:8081/add_user
Создали пользователя и получили его UUID. Запомним его.
curl -X POST --data "description=My first tiktok" url/add_video
Представим, что пользователь добавил свое первое видео с описанием. Мы также получили UUID видеоролика. Его тоже запомним.
In order to «like» the video, you need to specify the user UUID and the video UUID from the previous steps. Substitute the ellipses in the command below with the corresponding UUIDs:
curl -X POST --data "video_id=...&user_id=..." url/like_video
Получится примерно вот так:
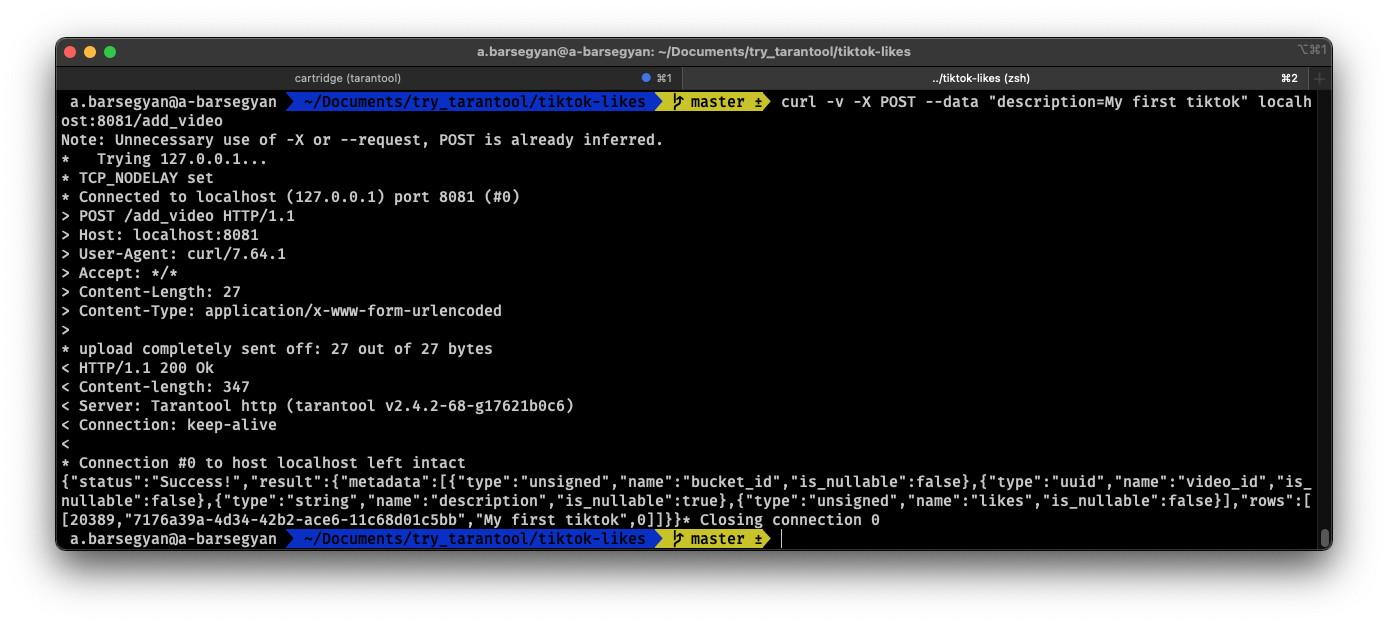
Тестовые запросы в консоли
В нашем примере «лайкать» видео можно сколько угодно раз. Хоть в
реальной жизни это и лишено смысла, но это поможет нам понять, как работает шардирование — а точнее, параметр sharding_key.
Для спейса likes мы указали sharding_key — video_id. Такой
же sharding_key мы указали и для спейса videos. Это означает,
что лайки будут храниться на том же storage, где и видео. Это обеспечивает локальность по данным при хранении и позволяет
за один сетевой поход в storage получить необходимую информацию.
Подробности описаны на следующем шаге.
Примечание
The following instructions are for Tarantool Enterprise Edition and the Try Tarantool cloud service.
The Space-Explorer tool is unavailable in the open-source version. Use the console to view data.
Подробности о просмотре данных читайте в нашей документации. О том, как подключиться к экземпляру Tarantool, читайте в базовом руководстве по Tarantool.
Переходим на вкладку «Space-Explorer» и видим все узлы в кластере. Так как у нас пока поднят всего один storage и один router, данные хранятся только на одном узле.
Let’s go to the node s1-master: click «Connect» and select the necessary space.
Check that everything is in place and move on.
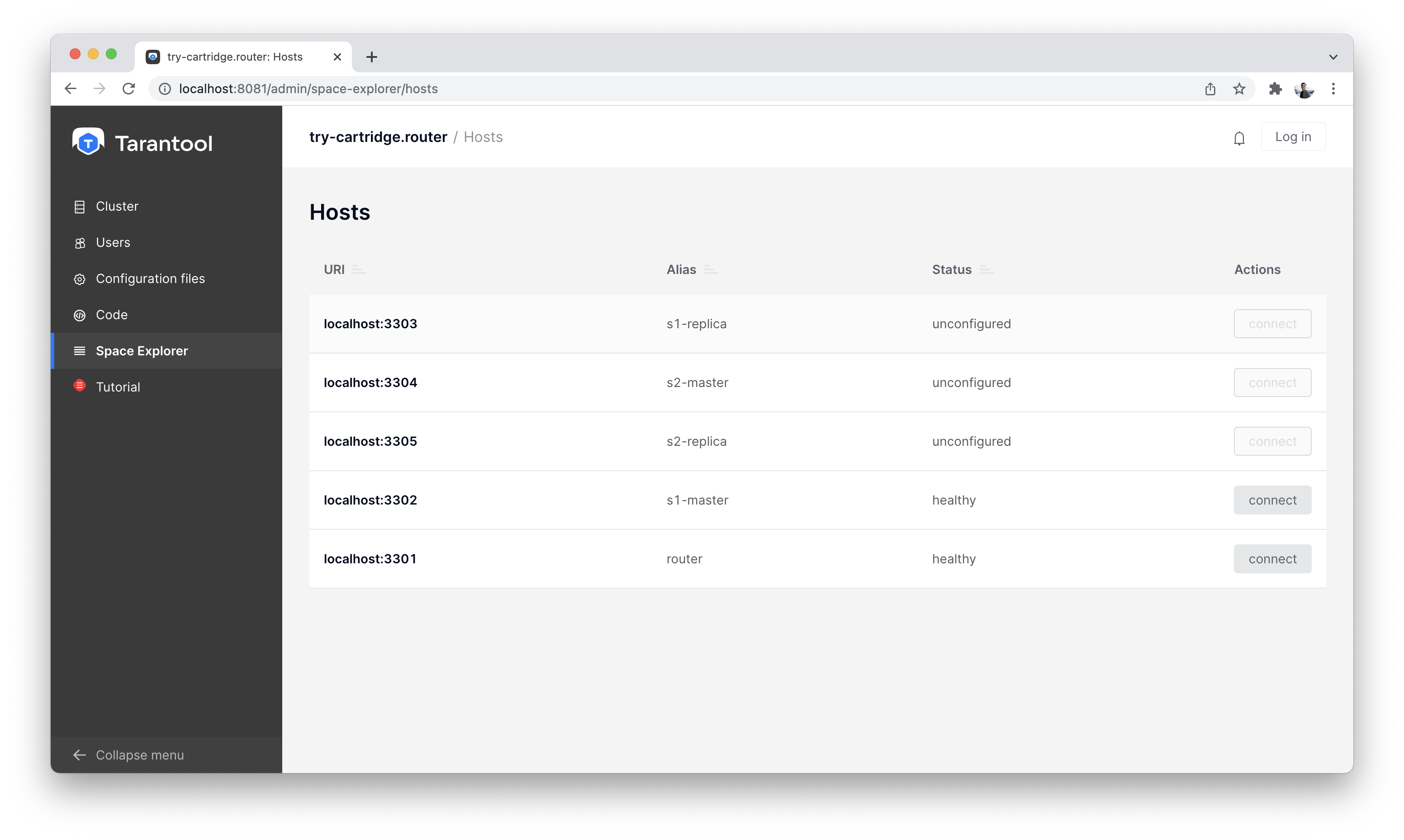
Space-Explorer, список хостов
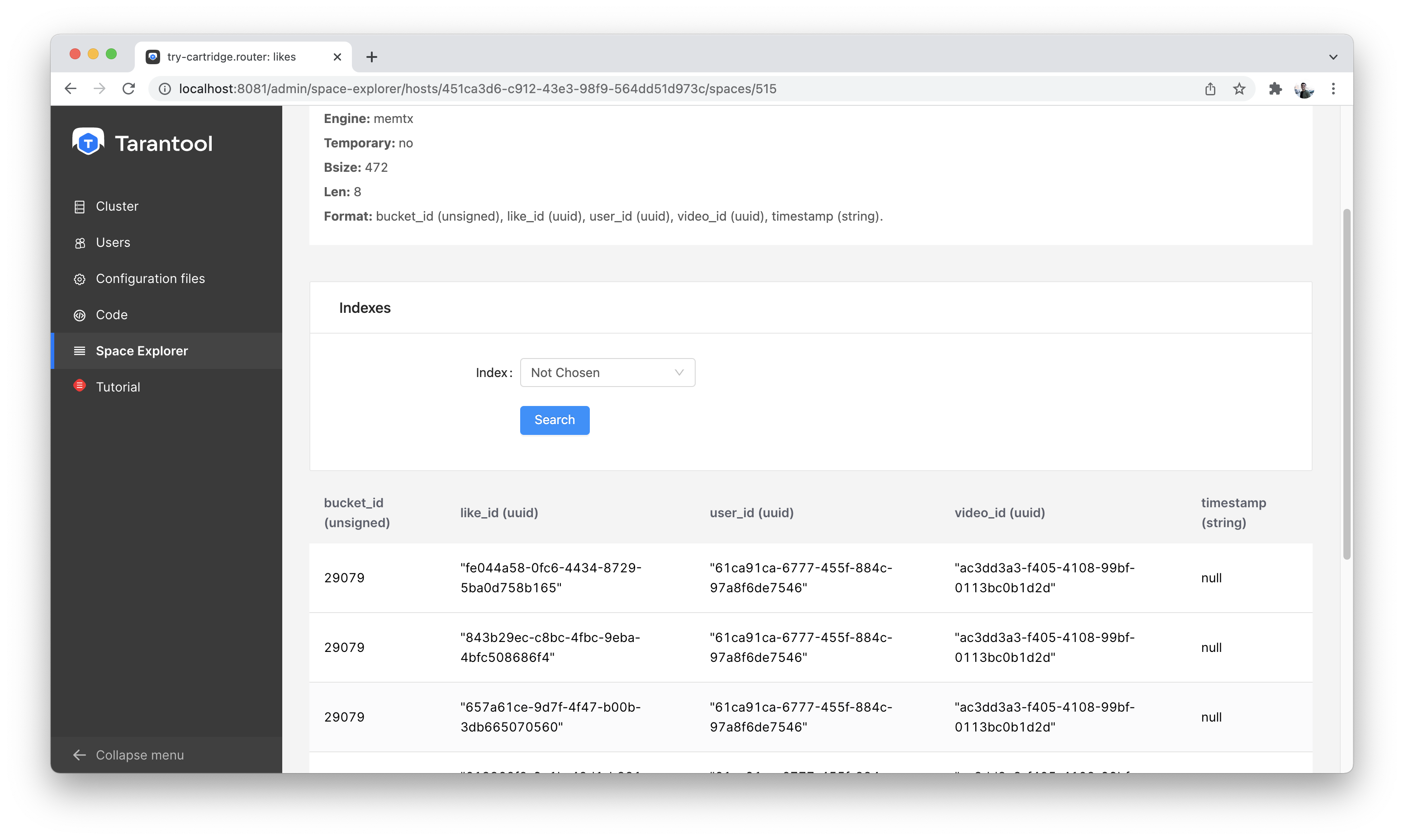
Space-Explorer, просмотр лайков
Создадим второй шард. Открываем вкладку «Cluster», выбираем
s2-master и нажимаем «Configure». Выбираем роли так, как на картинке:

Cluster, экран конфигурации нового шарда
Щелкаем на нужные роли и создаем шард (набор реплик).
Теперь у нас есть два шарда — два логических узла, которые будут
разделять между собой данные. Роутер сам решает, какие данные на какой шард положить. По умолчанию, он просто использует хеш-функцию от поля sharding_key , которое мы указали в DDL.
Чтобы задействовать новый шард, надо выставить для него вес 1. Заходим снова на вкладку «Cluster», переходим в настройки s2-master, указываем для Replica set weight значение 1 и применяем.
Кое-что уже произошло. Зайдем в space-explorer и перейдем на узел
s2-master. Оказывается, часть данных с первого шарда переехала сюда автоматически! Масштабирование происходит автоматически.
Теперь попробуем добавить еще данных в кластер через HTTP API. Можем проверить и убедиться, что новые данные также равномерно распределяются на два шарда.
Выставляем в настройках s1-master значение 0 для Replica set weight и применяем. Ждем пару секунд, заходим в space-explorer и смотрим на данные в s2-master: все данные автоматически мигрировали на оставшийся шард.
Теперь можно смело отключать первый шард, если вам понадобилось провести служебные работы.