Tarantool 3.0
Release date: December 26, 2023
Releases on GitHub: v. 3.0.2, v. 3.0.1, v. 3.0.0
The 3.0 release of Tarantool introduces a new declarative approach for configuring a cluster, a new visual tool – Tarantool Cluster Manager, and many other new features and fixes. This document provides an overview of the most important features for the Community and Enterprise editions.
- New declarative configuration
- Tarantool Cluster Manager
- Administration and maintenance
- Developing applications
- Stability
Starting with the 3.0 version, Tarantool provides the ability to configure the full topology of a cluster using a declarative YAML configuration instead of configuring each instance using a dedicated Lua script. With a new approach, you can write a local configuration in a YAML file for each instance or store configuration data in one reliable place, for example, a Tarantool or an etcd cluster.
The example below shows how a configuration of a small sharded cluster might look. In the diagram below, the cluster includes 5 instances: one router and 4 storages, which constitute two replica sets. For each replica set, the master instance is specified manually.
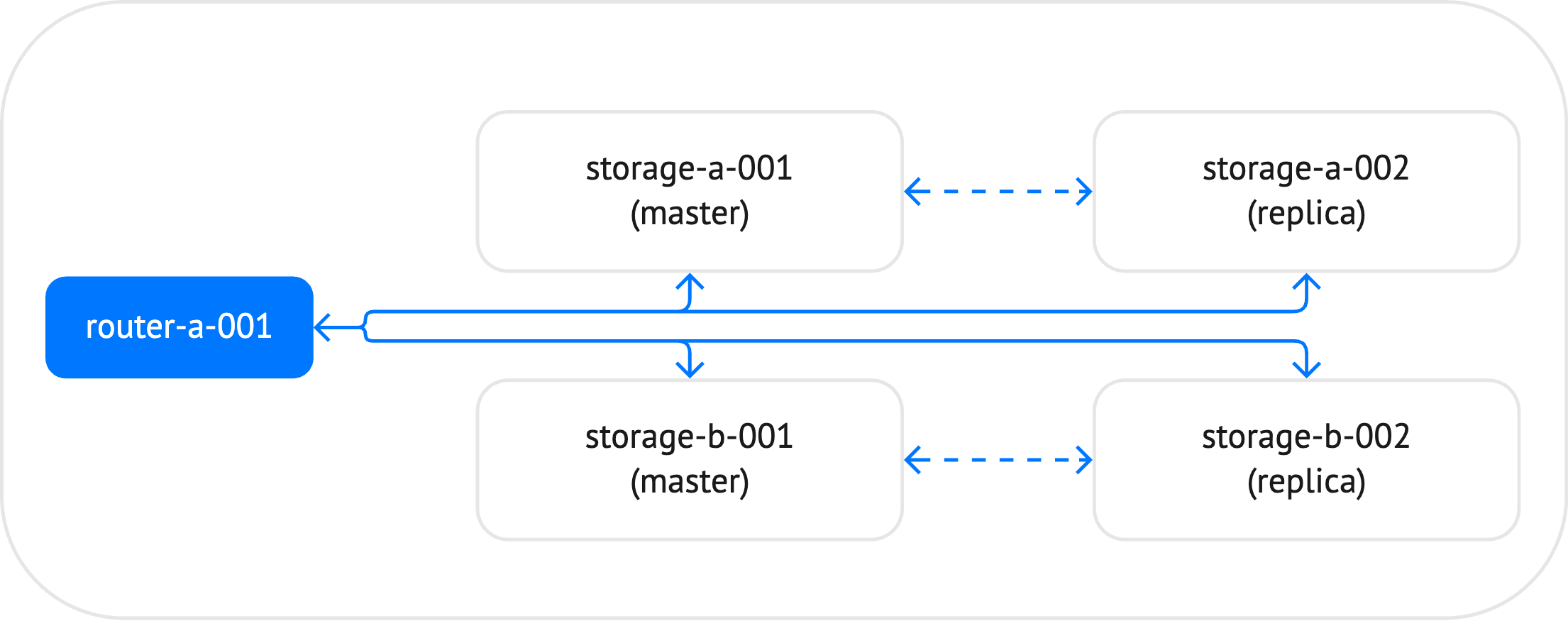
The example below demonstrates how a topology of such a cluster might look in a YAML configuration file:
groups:
storages:
app:
module: storage
sharding:
roles: [storage]
replication:
failover: manual
replicasets:
storage-a:
leader: storage-a-001
instances:
storage-a-001:
iproto:
listen:
- uri: '127.0.0.1:3302'
storage-a-002:
iproto:
listen:
- uri: '127.0.0.1:3303'
storage-b:
leader: storage-b-001
instances:
storage-b-001:
iproto:
listen:
- uri: '127.0.0.1:3304'
storage-b-002:
iproto:
listen:
- uri: '127.0.0.1:3305'
routers:
app:
module: router
sharding:
roles: [router]
replicasets:
router-a:
instances:
router-a-001:
iproto:
listen:
- uri: '127.0.0.1:3301'
You can find the full sample in the GitHub documentation repository: sharded_cluster.
The latest version of the tt utility provides the ability to manage Tarantool instances configured using a new approach. You can start all instances in a cluster by executing one command, check the status of instances, or stop them:
$ tt start sharded_cluster
• Starting an instance [sharded_cluster:storage-a-001]...
• Starting an instance [sharded_cluster:storage-a-002]...
• Starting an instance [sharded_cluster:storage-b-001]...
• Starting an instance [sharded_cluster:storage-b-002]...
• Starting an instance [sharded_cluster:router-a-001]...
Tarantool Enterprise Edition enables you to store configuration data in one reliable place, for example, an etcd cluster. To achieve this, you need to configure connection options in the config.etcd section of the configuration file, for example:
config:
etcd:
endpoints:
- http://localhost:2379
prefix: /myapp
username: sampleuser
password: '123456'
Using the configuration above, a Tarantool instance searches for a cluster configuration by the following path:
http://localhost:2379/myapp/config/*
Tarantool 3.0 Enterprise Edition comes with a brand new visual tool – Tarantool Cluster Manager (TCM). It provides a web-based user interface for managing, configuring, and monitoring Tarantool EE clusters that use centralized configuration storage.
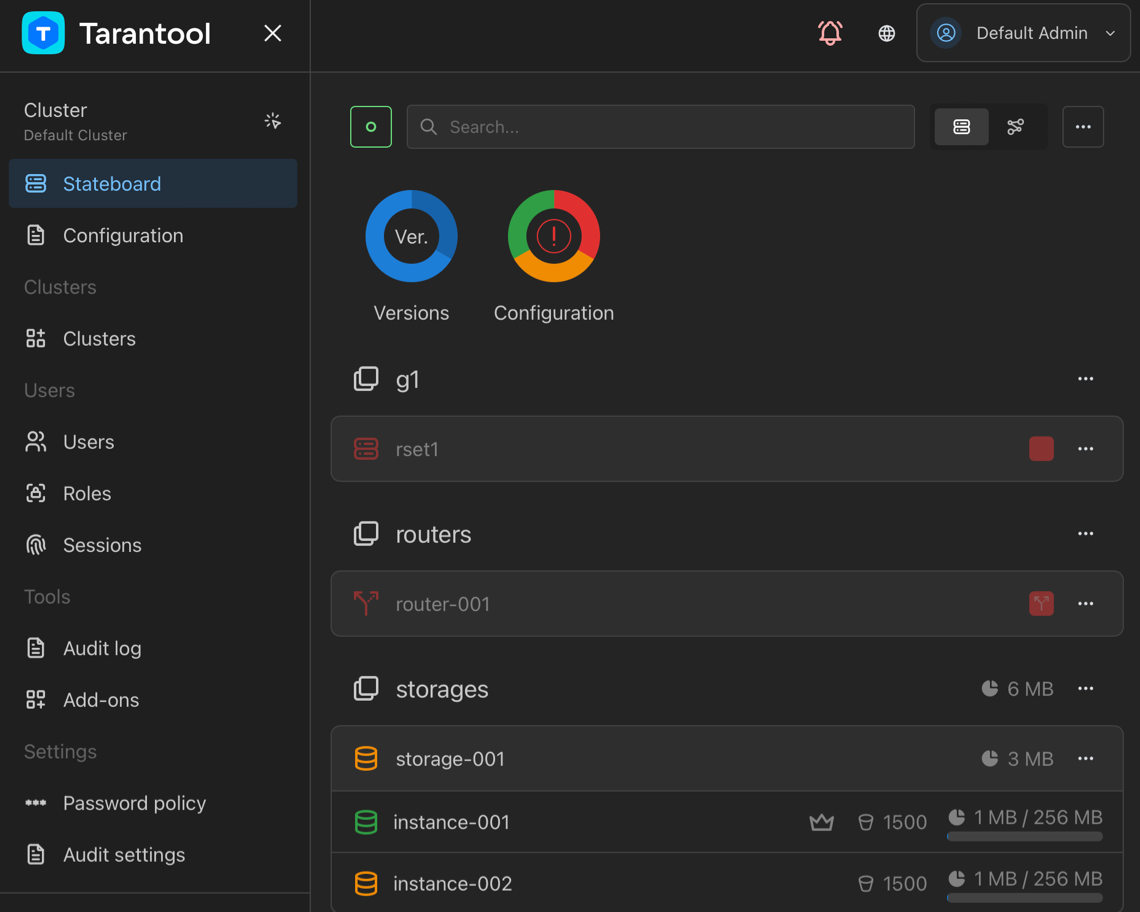
TCM can manage multiple clusters and covers a wide range of tasks, from writing a cluster’s configuration to executing commands interactively on specific instances.
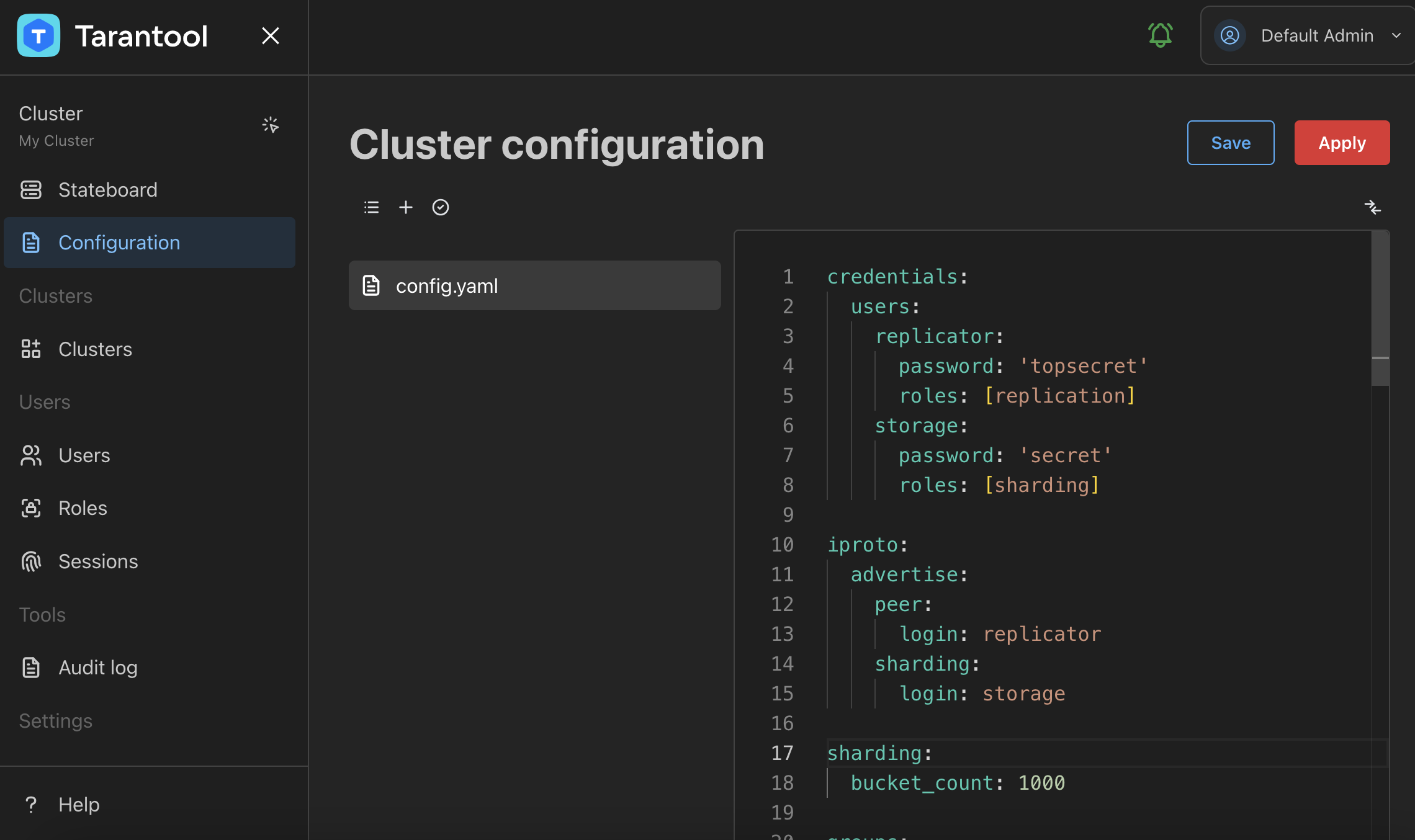
TCM’s role-based access control system lets you manage users’ access to clusters, their configurations, and stored data.

The built-in customizable audit logging mechanism and LDAP authentication make TCM a suitable solution for different enterprise security requirements.
Starting with 3.0, Tarantool provides extended statistics about memory consumption for the given space or specific tuples.
Usually, the space_object:bsize() method is used to get the size of memory occupied by the specified space:
app:instance001> box.space.books:bsize()
---
- 70348673
...
In addition to the actual data, the space requires additional memory to store supplementary information. You can see the total memory usage using box.slab.info():
app:instance001> box.slab.info().items_used
---
- 75302024
...
A new space_object:stat() <box_space-stat> method allows you to determine how the additional 5 Mb of memory is used:
app:instance001> box.space.books:stat()
---
- tuple:
memtx:
waste_size: 1744011
data_size: 70348673
header_size: 2154132
field_map_size: 0
malloc:
waste_size: 0
data_size: 0
header_size: 0
field_map_size: 0
...
The above report gives the following information:
header_sizeandfield_map_size: the size of service information.data_size: the actual size of data, which equals tospace_object:bsize().waste_size: the size of memory wasted due to internal fragmentation in the slab allocator.
To get such information about a specific tuple, use tuple_object:info():
app:instance001> box.space.books:get('1853260622'):info()
---
- data_size: 277
waste_size: 9
arena: memtx
field_map_size: 0
header_size: 10
...
The new version includes the capability to choose a bootstrap leader for a replica set manually. The bootstrap leader is a node that creates an initial snapshot and registers all the replicas in a replica set.
First, you need to set replication.bootstrap_strategy to config.
Then, use the <replicaset_name>.bootstrap_leader option to specify a bootstrap leader.
groups:
group001:
replicasets:
replicaset001:
replication:
bootstrap_strategy: config
bootstrap_leader: instance001
instances:
instance001:
iproto:
listen:
- uri: '127.0.0.1:3301'
instance002:
iproto:
listen:
- uri: '127.0.0.1:3302'
instance003:
iproto:
listen:
- uri: '127.0.0.1:3303'
Note
Note that in 3.0, the replication_connect_quorum option is removed. This option was used to specify the number of nodes to be up and running for starting a replica set.
With the 3.0 version, Tarantool Enterprise Edition provides a set of new features that enhance security in your cluster:
Introduced the
secure_erasingconfiguration option that forces Tarantool to overwrite a data file a few times before deletion to render recovery of a deleted file impossible. With the new configuration approach, you can enable this capability as follows:security: secure_erasing: true
This option can be also set using the
TT_SECURITY_SECURE_ERASINGenvironment variable.Added the
auth_retriesoption that configures the maximum number of authentication retries before throttling is enabled. You can configure this option as follows:security: auth_retries: 3
Added the capability to use the new SSL certificate with the same name by reloading the configuration. To do this, use the
reload()function provided by the newconfigmodule:app:instance001> require('config'):reload() --- ...
Tarantool Enterprise Edition includes the following new features for audit logging:
- Added a unique identifier (UUID) to each audit log entry.
- Introduced audit log severity levels. Each system audit event now has a severity level determined by its importance.
- Added the
audit_log.audit_spacesoption that configures the list of spaces for which data operation events should be logged. - Added the
audit_log.audit_extract_keyoption that forces the audit subsystem to log the primary key instead of a full tuple in DML operations. This might be useful for reducing audit log size in the case of large tuples.
The sample audit log configuration in the 3.0 version might look as follows, including new audit_spaces and audit_extract_key options:
audit_log:
to: file
file: audit_tarantool.log
filter: [ddl,dml]
spaces: [books]
extract_key: true
With this configuration, an audit log entry for a DELETE operation may look like below:
{
"time": "2023-12-19T10:09:44.664+0000",
"uuid": "65901190-f8a6-45c1-b3a4-1a11cf5c7355",
"severity": "VERBOSE",
"remote": "unix/:(socket)",
"session_type": "console",
"module": "tarantool",
"user": "admin",
"type": "space_delete",
"tag": "",
"description": "Delete key [\"0671623249\"] from space books"
}
The entry includes the new uuid and severity fields.
The last description field gives only the information about the key of the deleted tuple.
The flight recorder available in the Enterprise Edition is an event collection tool that gathers various information about a working Tarantool instance.
With the 3.0 version, you can read flight recordings using the API provided by the flightrec module.
To enable the flight recorder in a YAML file, set flightrec.enabled to true:
flightrec:
enabled: true
Then, you can use the Lua API to open and read *.ttfr files:
app:instance001> flightrec = require('flightrec')
---
...
app:instance001> flightrec_file = flightrec.open('var/lib/instance001/20231225T085435.ttfr')
---
...
app:instance001> flightrec_file
---
- sections: &0
requests:
size: 10485760
metrics:
size: 368640
logs:
size: 10485760
was_closed: false
version: 0
pid: 1350
...
app:instance001> for i, r in flightrec_file.sections.logs:pairs() do record = r; break end
---
...
app:instance001> record
---
- level: INFO
fiber_name: interactive
fiber_id: 103
cord_name: main
file: ./src/box/flightrec.c
time: 2023-12-25 08:50:12.275
message: 'Flight recorder: configuration has been done'
line: 727
...
app:instance001> flightrec_file:close()
---
...
With this release, the approach to delivering Tarantool to end users in DEB and RPM packages is slightly revised. In the previous versions, Tarantool was built for the most popular Linux distributions and their latest version.
Starting with this release, only two sets of DEB and RPM packages are delivered. The difference is that these packages include a statically compiled Tarantool binary. This approach provides the ability to install DEB and RPM packages on any Linux distributions that are based on СentOS and Debian.
To ensure that Tarantool works for a wide range of different distributions and their versions, RPM and DEB packages are prepared on CentOS 7 with glibc 2.17.
In the previous versions, Tarantool already supported the varbinary type for storing data.
But working with varbinary database fields required workarounds, such as using C to process such data.
The 3.0 version includes a new varbinary module for working with varbinary objects.
The module implements the following functions:
varbinary.new()- constructs a varbinary object from a plain string.varbinary.is()- returns true if the argument is a varbinary object.
In the example below, an object is created from a string:
local varbinary = require('varbinary')
local bin = varbinary.new('Hello world!')
The built-in decoders now decode binary data fields to a varbinary object by default:
local varbinary = require('varbinary')
local msgpack = require('msgpack')
varbinary.is(msgpack.decode('\xC4\x02\xFF\xFE'))
--[[
---
- true
...
]]
varbinary.is(yaml.decode('!!binary //4='))
--[[
---
- true
...
]]
This also implies that the data stored in the database under the varbinary field type is now returned to Lua not as a plain string but as a varbinary object.
It’s possible to revert to the old behavior by toggling the new binary_data_decoding compat option because this change may break backward compatibility:
compat:
binary_data_decoding: old
You can now assign the default values for specific fields
when defining a space format.
In this example, the isbn and title fields have the specified default values:
box.schema.space.create('books')
box.space.books:format({
{ name = 'id', type = 'unsigned' },
{ name = 'isbn', type = 'string', default = '9990000000000' },
{ name = 'title', type = 'string', default = 'New awesome book' },
{ name = 'year_of_publication', type = 'unsigned', default = 2023 }
})
box.space.books:create_index('primary', { parts = { 'isbn' } })
If you insert a tuple with missing fields, the default values are inserted:
app:instance001> box.space.books:insert({ 1000, nil, nil, nil })
---
- [1000, '9990000000000', 'New awesome book', 2023]
...
You can also provide a custom logic for generating a default value.
To achieve this, create a function using box.schema.func.create:
box.schema.func.create('current_year', {
language = 'Lua',
body = "function() return require('datetime').now().year end"
})
Then, assign the function name to default_func when defining a space format:
box.space.books:format({
-- ... --
{ name = 'year_of_publication', type = 'unsigned', default_func = 'current_year' }
})
Learn more in Default values.
In the 3.0 version, the API for creating triggers is completely reworked.
A new trigger module is introduced, allowing you to set handlers on both predefined and custom events.
To create the trigger, you need to:
- Provide an event name used to associate the trigger with.
- Define the trigger name.
- Provide a trigger handler function.
The code snippet below shows how to subscribe to changes in the books space:
local trigger = require('trigger')
trigger.set(
'box.space.books.on_replace', -- event name
'some-custom-trigger', -- trigger name
function(...)
-- trigger handler
end
)
The 2.11 release introduced the following features:
- Read views are in-memory snapshots of the entire database that aren’t affected by future data modifications.
- Pagination for getting data in chunks.
With the 3.0 release, a read view object supports the after and fetch_pos arguments for the select and pairs methods:
-- Select first 3 tuples and fetch a last tuple's position --
app:instance001> result, position = read_view1.space.bands:select({}, { limit = 3, fetch_pos = true })
---
...
app:instance001> result
---
- - [1, 'Roxette', 1986]
- [2, 'Scorpions', 1965]
- [3, 'Ace of Base', 1987]
...
app:instance001> position
---
- kQM
...
-- Then, you can pass this position as the 'after' parameter --
app:instance001> read_view1.space.bands:select({}, { limit = 3, after = position })
---
- - [4, 'The Beatles', 1960]
- [5, 'Pink Floyd', 1965]
- [6, 'The Rolling Stones', 1962]
...
Starting with the 3.0 version, the IPROTO protocol is extended to support for sending names of tuple fields in the IPROTO_CALL and other IPROTO responses. This simplifies the development of Tarantool connectors and also simplifies handling tuples received from remote procedure calls or from routers.
It’s possible to revert to the old behavior by toggling the box_tuple_extension compat option:
compat:
box_tuple_extension: old
Starting with 3.0, names in SQL, for example, table, column, or constraint names are case-sensitive.
Before the 3.0 version, the query below created a MYTABLE table:
CREATE TABLE MyTable (i INT PRIMARY KEY);
To create the MyTable table, you needed to enclose the name into double quotes:
CREATE TABLE "MyTable" (i INT PRIMARY KEY);
Starting with 3.0, names are case-sensitive, and double quotes are no longer needed:
CREATE TABLE MyTable (i INT PRIMARY KEY);
For backward compatibility, the new version also supports a second lookup using an uppercase name.
This means that the query below tries to find the MyTable table and then MYTABLE:
SELECT * FROM MyTable;
The 3.0 release includes a fix for the gh-562 LuaJIT issue related to the inability to handle internal compiler on-trace errors using pcall.
The examples of such errors are:
- An
Out of memoryerror might occur forselectqueries returning a large amount of data. - A
Table overflowerror is raised when exceeding the maximum number of keys in a table.
The script below tries to fill a Lua table with a large number of keys:
local function memory_payload()
local t = {}
for i = 1, 1e10 do
t[ffi.new('uint64_t')] = i
end
end
local res, err = pcall(memory_payload)
print(res, err)
In the previous Tarantool version with the 32-bit Lua GC, this script causes the following error despite using pcall:
PANIC: unprotected error in call to Lua API (not enough memory)
For Tarantool with the 64-bit Lua GC, this script causes a Table overflow error:
PANIC: unprotected error in call to Lua API (table overflow)
Starting with the 3.0 version, these errors are handled correctly with the following outputs:
false not enough memory -- 32-bit Lua GC
false table overflow -- 64-bit Lua GC
As a result, Tarantool 3.0 becomes more stable in cases when user scripts include erroneous code.